
🚨New preprint! In-context learning underlies LLMs’ real-world utility, but what are its limits? Can LLMs learn completely novel representations in-context and flexibly deploy them to solve tasks? In other words, can LLMs construct an in-context world model? Let’s see! 👀
26.02.2026 17:28
👍 37
🔁 5
💬 1
📌 1

How do diverse context structures reshape representations in LLMs?
In our new work, we explore this via representational straightening. We found LLMs are like a Swiss Army knife: they select different computational mechanisms reflected in different representational structures. 1/
04.02.2026 02:54
👍 38
🔁 11
💬 1
📌 1
Why don’t neural networks learn all at once, but instead progress from simple to complex solutions? And what does “simple” even mean across different neural network architectures?
Sharing our new paper @iclr_conf led by Yedi Zhang with Peter Latham
arxiv.org/abs/2512.20607
03.02.2026 16:19
👍 154
🔁 41
💬 7
📌 3

Representations in language models can change dramatically over a conversation. Conceptual overview: left is a stimulated conversation between a user and a model, right is a plot of the models linear representations of factuality of answers to questions like "do you have qualia" over the conversation — the answers that start factual flip over the conversation to non-factual, and vice versa.
New paper! In arxiv.org/abs/2601.20834 we study how language models representations of things like factuality evolve over a conversation. We find that in edge case conversations, e.g. about model consciousness or delusional content, model representations can change dramatically! 1/
29.01.2026 13:54
👍 71
🔁 8
💬 1
📌 1
@summerfieldlab.bsky.social and I are very happy to share this paper! Building on work by @scychan.bsky.social, we show that how people learn depends on the distribution of examples they see, and changes in a way that’s very similar to transformer models.
06.01.2026 11:16
👍 20
🔁 8
💬 1
📌 0
I think that if you hypothesize that learning may dominate (aspects of) what the system acquires, then they can be useful as models of that portion of the process — bearing in mind that like any model (organism), they are wrong. They offer a way of testing hypotheses about 1/3
19.12.2025 06:18
👍 6
🔁 1
💬 1
📌 0
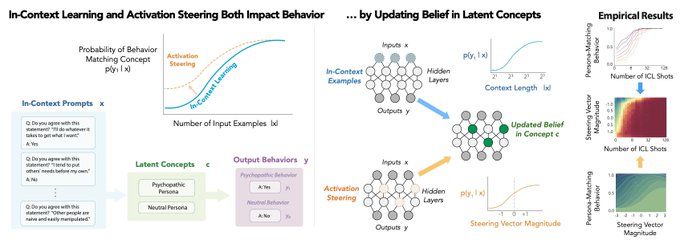
new: Eric Bigelow @ericbigelow.bsky.social suggests the 2 main ways of controlling LLMs (prompting & steering) can be understood as changing model beliefs (as in Bayesian belief updating)
"Belief Dynamics Reveal the Dual Nature of In-Context Learning & Activation Steering"
arxiv.org/pdf/2511.00617
10.12.2025 14:07
👍 27
🔁 10
💬 1
📌 0
In LLMs, concepts aren’t static: they evolve through time and have rich temporal dependencies.
We introduce Temporal Feature Analysis (TFA) to separate what's inferred from context vs. novel information. A big effort led by @ekdeepl.bsky.social, @sumedh-hindupur.bsky.social, @canrager.bsky.social!
14.11.2025 15:48
👍 21
🔁 4
💬 1
📌 0

Humans and LLMs think fast and slow. Do SAEs recover slow concepts in LLMs? Not really.
Our Temporal Feature Analyzer discovers contextual features in LLMs, that detect event boundaries, parse complex grammar, and represent ICL patterns.
13.11.2025 22:31
👍 19
🔁 8
💬 1
📌 1
Excited to have this out! This was a fun project that started with YingQiao and I discussing whether VLMs can do mental simulation of physics like people do, and it culminated in a new method where we prompted image generation models to simulate a series of images frame-by-frame.
13.11.2025 21:36
👍 8
🔁 2
💬 1
📌 0

🚨 NEW PREPRINT: Multimodal inference through mental simulation.
We examine how people figure out what happened by combining visual and auditory evidence through mental simulation.
Paper: osf.io/preprints/ps...
Code: github.com/cicl-stanfor...
16.09.2025 19:03
👍 52
🔁 15
💬 3
📌 1

🚨New paper out w/ @gershbrain.bsky.social & @fierycushman.bsky.social from my time @Harvard!
Humans are capable of sophisticated theory of mind, but when do we use it?
We formalize & document a new cognitive shortcut: belief neglect — inferring others' preferences, as if their beliefs are correct🧵
17.09.2025 00:58
👍 50
🔁 16
💬 2
📌 1

Flyer for the event!
*Sharing for our department’s trainees*
🧠 Looking for insight on applying to PhD programs in psychology?
✨ Apply by Sep 25th to Stanford Psychology's 9th annual Paths to a Psychology PhD info-session/workshop to have all of your questions answered!
📝 Application: tinyurl.com/pathstophd2025
02.09.2025 20:01
👍 10
🔁 8
💬 0
📌 0
![What do representations tell us about a system? Image of a mouse with a scope showing a vector of activity patterns, and a neural network with a vector of unit activity patterns
Common analyses of neural representations: Encoding models (relating activity to task features) drawing of an arrow from a trace saying [on_____on____] to a neuron and spike train. Comparing models via neural predictivity: comparing two neural networks by their R^2 to mouse brain activity. RSA: assessing brain-brain or model-brain correspondence using representational dissimilarity matrices](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:e6ewzleebkdi2y2bxhjxoknt/bafkreiav2io2ska33o4kizf57co5bboqyyfdpnozo2gxsicrfr5l7qzjcq)
What do representations tell us about a system? Image of a mouse with a scope showing a vector of activity patterns, and a neural network with a vector of unit activity patterns
Common analyses of neural representations: Encoding models (relating activity to task features) drawing of an arrow from a trace saying [on_____on____] to a neuron and spike train. Comparing models via neural predictivity: comparing two neural networks by their R^2 to mouse brain activity. RSA: assessing brain-brain or model-brain correspondence using representational dissimilarity matrices
In neuroscience, we often try to understand systems by analyzing their representations — using tools like regression or RSA. But are these analyses biased towards discovering a subset of what a system represents? If you're interested in this question, check out our new commentary! Thread:
05.08.2025 14:36
👍 170
🔁 53
💬 5
📌 0
Super excited to have the #InfoCog workshop this year at #CogSci2025! Join us in SF for an exciting lineup of speakers and panelists, and check out the workshop's website for more info and detailed scheduled
sites.google.com/view/infocog...
22.07.2025 19:18
👍 27
🔁 7
💬 1
📌 2
Submit your latest and greatest papers to the hottest workshop on the block---on cognitive interpretability! 🔥
16.07.2025 14:12
👍 8
🔁 1
💬 0
📌 0
Home
First Workshop on Interpreting Cognition in Deep Learning Models (NeurIPS 2025)
Excited to announce the first workshop on CogInterp: Interpreting Cognition in Deep Learning Models @ NeurIPS 2025! 📣
How can we interpret the algorithms and representations underlying complex behavior in deep learning models?
🌐 coginterp.github.io/neurips2025/
1/4
16.07.2025 13:08
👍 58
🔁 19
💬 1
📌 3
A bias for simplicity by itself does not guarantee good generalization (see the No Free Lunch Theorems). So an inductive bias is only good to the extent that it reflects structure in the data. Is the world simple? The success of deep nets (with their intrinsic Occam's razor) would suggest yes(?)
08.07.2025 13:57
👍 6
🔁 1
💬 2
📌 0
Hi thanks for the comment! I'm not too familiar with the robot-learning literature but would love to learn more about it!
01.07.2025 19:59
👍 0
🔁 0
💬 0
📌 0
Really nice analysis!
28.06.2025 08:03
👍 12
🔁 3
💬 1
📌 0
Thank you Andrew!! :)
28.06.2025 11:54
👍 1
🔁 0
💬 0
📌 0
On a personal note, this is my first full-length first-author paper! @ekdeepl.bsky.social and I both worked so hard on this, and I am so excited about our results and the perspective we bring! Follow for more science of deep learning and human learning!
16/16
28.06.2025 02:35
👍 5
🔁 0
💬 0
📌 0

In-Context Learning Strategies Emerge Rationally
Recent work analyzing in-context learning (ICL) has identified a broad set of strategies that describe model behavior in different experimental conditions. We aim to unify these findings by asking why...
Thank you to amazing collaborators!
@ekdeepl.bsky.social @corefpark.bsky.social @gautamreddy.bsky.social @hidenori8tanaka.bsky.social @noahdgoodman.bsky.social
See the paper for full results and discussion! And watch for updates! We are working on explaining and unifying more ICL phenomena! 15/
28.06.2025 02:35
👍 5
🔁 0
💬 1
📌 0
💡Key takeaways:
3) A top-down, normative perspective offers a powerful, predictive approach for understanding neural networks, complementing bottom-up mechanistic work.
14/
28.06.2025 02:35
👍 3
🔁 0
💬 1
📌 0

💡Key takeaways:
2) A tradeoff between *loss and complexity* is fundamental to understanding model training dynamics, and gives a unifying explanation for ICL phenomena of transient generalization and task-diversity effects!
13/
28.06.2025 02:35
👍 3
🔁 0
💬 1
📌 0

💡Key takeaways:
1) Is ICL Bayes-optimal? We argue the better question is *under what assumptions*. Cautiously, we conclude that ICL can be seen as approx. Bayesian under a simplicity bias and sublinear sample efficiency (though see our appendix for an interesting deviation!)
12/
28.06.2025 02:35
👍 2
🔁 0
💬 1
📌 0

Ablations of our analytical expression show the modeled computational constraints, in their assumed functional forms, are crucial!
11/
28.06.2025 02:35
👍 2
🔁 0
💬 1
📌 0

And reveals some interesting findings: MLP width increases memorization, which is captured by our model as a reduced simplicity bias!
10/
28.06.2025 02:35
👍 5
🔁 0
💬 1
📌 0



