
Thanks! Would love for you to try it out. It does require a bit of time to setup, but we think it’s not overly tedious.
29.05.2025 14:37
👍 1
🔁 0
💬 0
📌 0
Thanks! Would love for you to try it out. It does require a bit of time to setup, but we think it’s not overly tedious.
Aaron Garvey and I would love to get feedback on toolkit or the paper
Garvey, Aaron G. and Simon J. Blanchard (2025). Generative AI as a Research Confederate: The LUCID Methodological Framework and Toolkit for Controlled Human-AI Interactions in Survey Research. papers.ssrn.com/sol3/papers....

Step 3: Adapt to your use case
Once the backend is live and you’ve picked a template, you can:
• Edit the prompt wording
• Change when/where GPT is used in the survey flow
There’s a walkthrough in the guide on how these parts connect.
lucidresearch.io/Step3-Custom...
Step 2: Choose a Qualtrics template
We’ve shared a few .QSF templates that show different ways GPT can be embedded into surveys:
• Simple conversational flow
• Between-subject manipulations
The goal is to give working examples that you can modify.
lucidresearch.io/Step2-Select...

Step 1: Deploy a backend to handle GPT
To keep OpenAI keys secure, we suggest deploying a small server (e.g. free on Vercel). This way, the GPT call happens outside of Qualtrics, and the key stays hidden.
We provide the code. No coding experience needed.
github.com/amgarv/LUCID...
Hi all hi 👋 We’ve been working on a toolkit to help people integrate GPT-based chatbots into Qualtrics surveys—securely and with no coding experience needed.
Step-by-step guide:
🔗 lucidresearch.io/getting-star...
See it in action:
🔍 uky.az1.qualtrics.com/jfe/form/SV_...
How it works ↓
#qualtrics
Tu m’as eu!
Define criticize? And in what format?

Totally fair. I wrote too quickly.
The example used here was about the effect of income on education. But I have the same struggle: I don’t know how easy it’d be to convince myself and the reviewers that latent IV is appropriate.
link.springer.com/journal/11129
I’m wondering if we’re going to see some sort of reverse snowbirds effect: Canadian academics in the US seeking to reaffiliate with Canadian institutions/centers and attend Canadian conference more.
Very nice table. It’s particularly striking to me that despite having fewer assumptions, my perception is that latent IVs still see so much less use. Do you discuss that in the chapter?
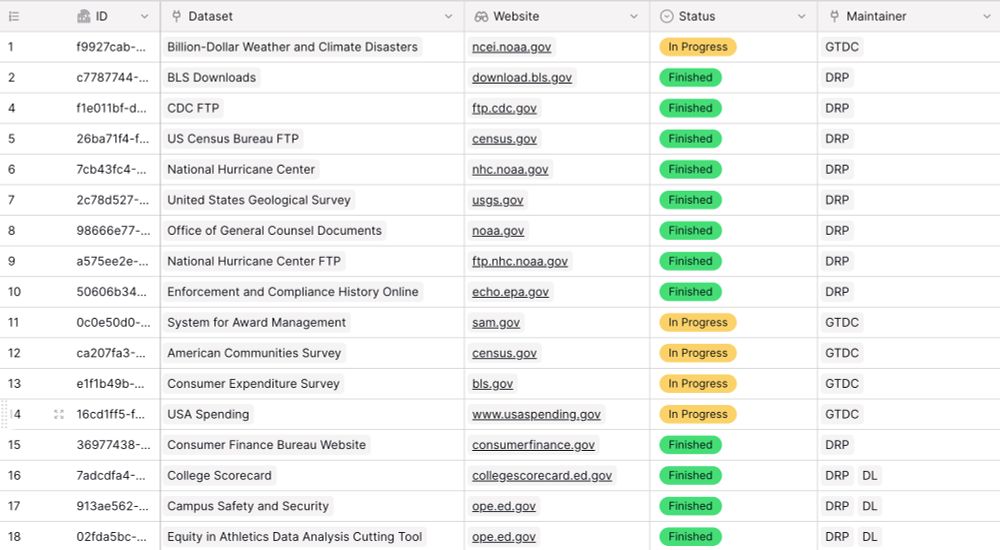
Our group has been hard at work to release a new tool: The Data Rescue Tracker. The tool aims to provide a consolidated overview of who is downloading which dataset from which government websites. Please share! www.datarescueproject.org/data-rescue-...
Have they appealed?

If anyone really wants know, for my guesstimate of HSA annualized rate, I used data from Investopedia for 2022 onward. For 2017-2021, I extrapolated based on historical trends, accounting for the low-rate environment during that period. www.investopedia.com/best-high-yi...
I had to look this up! The price went from $0.49 in 2017 to $0.73 today - a 48% (~5% annual return).
For comparison, high-yield savings accounts over the same period returned about 2.3% annually. But, if that $0.49 had been in the S&P 500, it be $1.56 (15%). Still, not bad for stamps!
Those would have been great schools for me!
What slowed adoption with first generation audio/video assistants is that they were largely ruled base and often "single turn" (i.e., no memory). It's now much easier to develop realtime voice chat agents that keep sessions in the context (e.g., platform.openai.com/docs/guides/...).

Sure, the LLM might be wrong, or perhaps it’s just demonstrating a bit of premonitory hallucination—seeing the Florida professor within before he does! ;)
Which deepseek were you running? Local or online? I’ve run ollama 70b locally, so I might try deepseek r1 70. I wouldn’t submit working or published papers to their GUI unless the paper is also on SSRN
If you ran OLS on 0/1 and SPSS provided you estimates, would you be upset it didn’t stop you to say you should run a logistic regression?
Different models have different uses. o1 is complex reasoning. OA offers help & globe icon (enables search) is even disabled in o1. Seems like enough to me.

o1 doesn’t have access to web search. Try 4o. help.openai.com/en/articles/...
Then we’ll see you on Red Note / the little red book? 😅
What a great game you chose to go to!
Valid point! But it’s not just about the lack of shrinkage. It also requires well-balanced data between subjects, which is rare unless N is large. Plus, it risks a loss of power by discarding within-subject variability that multilevel models can leverage.
🤦♂️
I only use Cloudresearch Connect, where there’s a “universal block list.” I’m assuming they monitor stats of users being added across such lists in addition to rejections. Is there a similar block list on prolific?
And they found the evidence to be compelling!
Thanks Felix! The part that was surprising to us that’s just how much similarity there is between people who post fake news and people who fact check them. They write very similarly. More work is needed to distangled them.
Great additions to JCR.

One way that the credit piece can be handled is by building it the full set of papers as part of a research dialog, when the issue is sufficiently big.