While our method can be applied to general purpose image generation, our method achieves the most dramatic savings (saves >75% vs standard diffusion) when examples are structurally similar. Some applications of this are style variation, subject variation, and virtual try-on.
6/
22.10.2025 20:22
👍 0
🔁 0
💬 1
📌 0

Interestingly, we observe that models trained using a text-to-image prior (bottom) generate high frequency details much later in the denoising process than without (top). This makes them ideal for sharing compute with our approach!
5/
22.10.2025 20:22
👍 1
🔁 0
💬 1
📌 0


Compared to standard diffusion (left), our method (right) generates images of comparable quality using a fraction of the compute. Exact savings depend on the prompt set, but we show that our method can save up to 74% of the total denoising steps required for standard diffusion!
4/
22.10.2025 20:22
👍 0
🔁 0
💬 1
📌 0
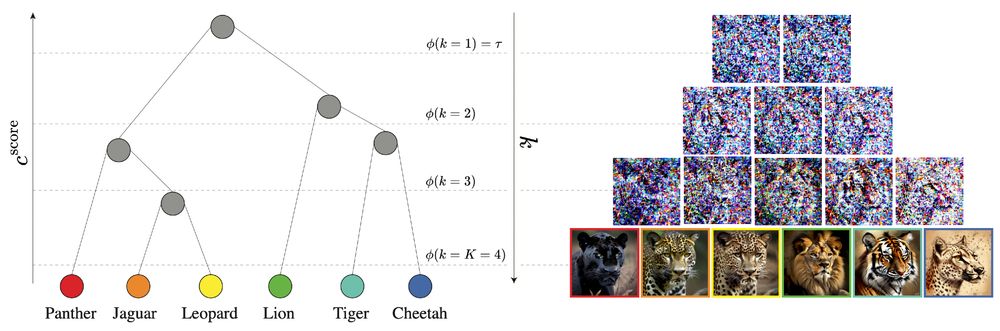
We construct a tree by hierarchically clustering prompts. We then map each denoising step k to a height in this tree, using the mean embedding of each cluster at this height as the condition. The steps gradually diverge from shared embeddings to individual prompt embeddings.
3/
22.10.2025 20:22
👍 0
🔁 0
💬 1
📌 0

We take advantage of the coarse-to-fine nature of diffusion generation: early timesteps generate low frequency structure and later timesteps produce high frequency details. Leveraging this, we share intermediate denoising results at early steps between similar examples.
2/
22.10.2025 20:22
👍 1
🔁 0
💬 1
📌 0
Excited to share our #ICCV2025 work Reusing Computation in Text-to-Image Diffusion for Efficient Generation of Image Sets!
Our method generates large sets of images using significantly less compute than standard diffusion.
📎https://ddecatur.github.io/hierarchical-diffusion/
1/
22.10.2025 20:22
👍 8
🔁 2
💬 1
📌 2



