
the heading of the paper "Intuitive insight: Fast associative processes drive sound creative thinking" at Cognition
1/13
New paper with @wimdeneys.bsky.social accepted at @cognitionjournal.bsky.social 🥳
Is creativity intuitive? 👩🎨
A 🧵👇
07.01.2026 17:40
👍 15
🔁 3
💬 1
📌 1

Abstract
Accurately quantifying belief strength in heuristics-and-biases tasks is crucial yet methodologically challenging. In this paper, we introduce an automated method leveraging large language models (LLMs) to systematically measure and manipulate belief strength. We specifically tested this method in the widely used “lawyer-engineer” base-rate neglect task, in which stereotypical descriptions (e.g., someone enjoying mathematical puzzles) conflict with normative base-rate information (e.g., engineers represent a very small percentage of the sample). Using this approach, we created an open-access database containing over 100,000 unique items systematically varying in stereotype-driven belief strength. Validation studies demonstrate that our LLM-derived belief strength measure correlates strongly with human typicality ratings and robustly predicts human choices in a base-rate neglect task. Additionally, our method revealed substantial and previously unnoticed variability in stereotype-driven belief strength in popular base-rate items from existing research, underlining the need to control for this in future studies. We further highlight methodological improvements achievable by refining the LLM prompt, as well as ways to enhance cross-cultural validity. The database presented here serves as a powerful resource for researchers, facilitating rigorous, replicable, and theoretically precise experimental designs, as well as enabling advancements in cognitive and computational modeling of reasoning. To support its use, we provide the R package baserater, which allows researchers to access the database to apply or adapt the method to their own research.
1/10
🚨 New preprint: Using Large Language Models to Estimate Belief Strength in Reasoning 🚨
When asked: "There are 995 politicians and 5 nurses. Person 'L' is kind. Is Person 'L' more likely to be a politician or a nurse?", most people will answer "nurse", neglecting the base-rate info.
A 🧵👇
16.10.2025 16:17
👍 13
🔁 3
💬 1
📌 1
NeurIPS Poster Curl Descent : Non-Gradient Learning Dynamics with Sign-Diverse PlasticityNeurIPS 2025
Excited to present my latest work, “Curl Descent: Non-Gradient Learning Dynamics with Sign-Diverse Plasticity,” this Friday at 11:00 AM at NeurIPS 2025!
Come by spotlight poster #3014 🎉 I’d love to discuss it with you:
neurips.cc/virtual/2025...
05.12.2025 03:15
👍 3
🔁 0
💬 0
📌 0

1/6 New preprint 🚀 How does the cortex learn to represent things and how they move without reconstructing sensory stimuli? We developed a circuit-centric recurrent predictive learning (RPL) model based on JEPAs.
🔗 doi.org/10.1101/2025...
Led by @atenagm.bsky.social @mshalvagal.bsky.social
27.11.2025 08:24
👍 141
🔁 42
💬 3
📌 4
9/10
Our work challenges the dominant view that learning must strictly follow a gradient. The diversity of plasticity rules in biology might not be a bug, but a feature—an evolutionary strategy leveraging non-gradient dynamics for more efficient and robust learning. 🌀
10.10.2025 17:53
👍 6
🔁 0
💬 1
📌 0

8/10
In this latter regime where only one rule-flipped synapse was introduced in the readout layer, curl descent can speed up learning in nonlinear networks. This result holds over a wide range of hyper-parameters.
10.10.2025 17:53
👍 1
🔁 0
💬 1
📌 0

7/10
The story is completely different for the readout layer. Surprisingly, even when curl terms make the solution manifold unstable, the network is still able to find other low-error regions!
10.10.2025 17:53
👍 0
🔁 0
💬 1
📌 0

6/10
But beware! If you add too many rule-flipped neurons in the hidden layer of a compressive network, the learning dynamics spiral into chaos, thereby destroying performance. The weights never settle, and the error stays high.
10.10.2025 17:53
👍 0
🔁 0
💬 1
📌 0

5/10
How does this scale up? We used random matrix theory to find that stability depends critically on network architecture. Expansive networks (input layer > hidden layer) are much more robust to curl terms, maintaining stable solutions even with many rule-flipped neurons.
10.10.2025 17:53
👍 0
🔁 0
💬 1
📌 0

4/10
Toy example : In a tiny 2-synapse network, curl descent can escape saddle points and converge faster than gradient descent by temporarily ascending the loss function. But it comes at a cost: half of the optimal solutions become unstable.
10.10.2025 17:53
👍 1
🔁 0
💬 1
📌 0

3/10
But can networks with such non-gradient learning dynamics still support meaningful optimization? We answer this question by focusing on an analytically tractable teacher-student framework, with 2-layer feedforward linear networks.
10.10.2025 17:53
👍 0
🔁 0
💬 1
📌 0

2/10
This is motivated by the diversity observed in the brain. A given weight update signal can have an opposite effects on a network's computation depending on the postsynaptic neuron (e.g. E/I), which is inconsistent with standard gradient descent.
10.10.2025 17:53
👍 0
🔁 0
💬 1
📌 0

1/10
We define the curl descent learning rule by flipping the sign of the updates given by gradient descent for some weights. These weights are chosen at the start of learning depending on the nature (rule-flipped or not) of the presynaptic neuron.
10.10.2025 17:53
👍 0
🔁 0
💬 1
📌 0

Curl Descent: Non-Gradient Learning Dynamics with Sign-Diverse Plasticity
Gradient-based algorithms are a cornerstone of artificial neural network training, yet it remains unclear whether biological neural networks use similar gradient-based strategies during learning. Expe...
🚨New spotlight paper at Neurips 2025🚨
We show that in sign-diverse networks, inherent non-gradient “curl” terms arise, and can, depending on network architecture, destabilize gradient-descent solutions or paradoxically accelerate learning beyond pure gradient flow.
🧵⬇️
www.arxiv.org/abs/2510.02765
10.10.2025 17:53
👍 13
🔁 4
💬 1
📌 0
Unable to access, but would love to read this ! Any full text link 👀?
13.06.2025 14:26
👍 0
🔁 0
💬 1
📌 0

Big week for astrocyte research: 3 new Science papers link astrocytes to behavior. We're excited to add to the momentum with our new PNAS paper: a theory, grounded in biology, proposing astrocytes as key players in memory storage and recall. w/ JJ Slotine and @krotov.bsky.social
(1/6)
28.05.2025 19:44
👍 35
🔁 13
💬 1
📌 0
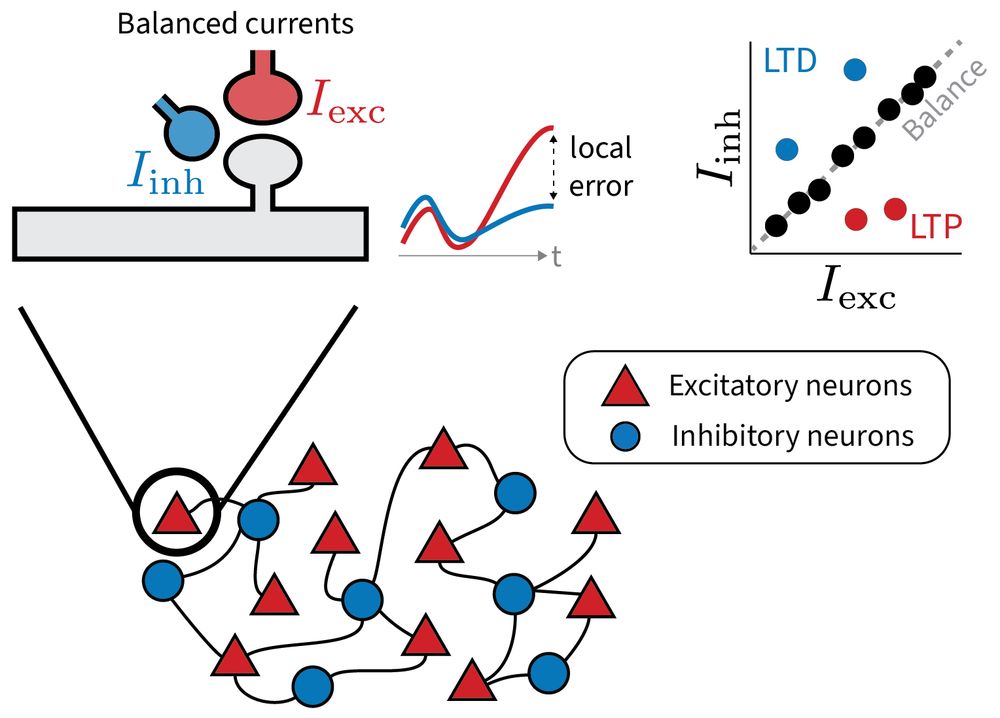
1/6 Why does the brain maintain such precise excitatory-inhibitory balance?
Our new preprint explores a provocative idea: Small, targeted deviations from this balance may serve a purpose: to encode local error signals for learning.
www.biorxiv.org/content/10.1...
led by @jrbch.bsky.social
27.05.2025 07:49
👍 181
🔁 57
💬 5
📌 3
Bluesky
9/9
A huge thank you to my co-first author @SharonIsraely and @OriRajchert, @LeeElmaleh, @RanHarel, @FirasMawase,
@kadmonj.bsky.social , and @yifatprut.bsky.social ut.bsky.social for their invaluable contributions and support throughout this journey. 🙏
22.03.2025 18:44
👍 1
🔁 1
💬 1
📌 0
8/n
1️⃣ Our study provides new insights into how cerebellar signals constrain cortical preparatory activity, promoting generalization and adaptation.
2️⃣ We demonstrate that in the absence of cerebellar signals, cortical mechanisms are harnessed to restore adaptation, albeit with reduced efficiency.
22.03.2025 18:35
👍 2
🔁 0
💬 1
📌 0

e Cross condition generalization performance relative to chance level (0.5) calculated for Control (blue) or HFS (red) conditions. Each dot represents a pair of dichotomies with shared symmetries (e.g., top-down dichotomy on left targets and top-down dichotomy on right targets). Diamonds represent the average CCGP over all dichotomies. f Quantification of generalization across all sessions, calculated for early (1–5) and late (>= 10) trials in the FF (blue) and HFS (red) conditions (n samples 4 and 35 for early and late FF trials respectively, and 4 and 30 samples for early and late FF- HFS trials. Data are presented as mean values ± SEM.
7/n
⚫ The increased dimensionality under HFS was accompanied by a decrease in generalization performance, both at the neural and behavioral levels.
22.03.2025 18:35
👍 1
🔁 0
💬 1
📌 0

a Dimensionality of neural activity estimated by the participation ratio (see Methods) at different epochs (blue bars: conrol, red: HFS). Asterisks denote signifcant differences in dimensionality (Dpca) during control vs. HFS conditions (resampling test with n = 1000, p < 0.01) d Illustration depicting the effects of the topology of the neural representation.
6/n
⚫ HFS led to higher dimensionality in neural activity, indicating a loss of structure in the neural representations, which is crucial for efficient motor learning and adaptation.
22.03.2025 18:35
👍 3
🔁 0
💬 1
📌 0

e Polar histograms of the neural angles calculated for one monkey (monkey S) by aggregating data from all cued targets and trials in the control FF conditions with the same forcefield direction (left: clockwise CW trials, right: counter-clockwise CCW trials). f Same as (e) but during FF combined with HFS (FF-HFS).
5/n
⚫ This compensation involved an angular shift in neural activity, suggesting a "re-aiming" strategy to handle the force field in the absence of cerebellar control.
22.03.2025 18:35
👍 0
🔁 0
💬 1
📌 0

c Decoding accuracy of adaptation conditions (NF vs. FF) based on epoch-specifc data for the control (blue bars) or HFS (red bars). Dashed line denotes chance level (0.5). Decoding accuracy values were obtained for different training and testing sets.
4/n
⚫ Under high-frequency stimulation (HFS), we observed a bigger difference between FF and null field (NF) neural activity, indicating a compensatory mechanism in the motor cortex to adapt to the perturbation.
22.03.2025 18:35
👍 0
🔁 0
💬 1
📌 0

f, g Effects of HFS on coordinated neural activity, calculated to a data set with reach to 8 targets for both control and HFS conditions (see Methods). PCA was performed in a similar manner as in (d, e), concatenating control (solid) and HFS (dashed) data (explained variance: PC1:0.2; PC2: 0.16; PC3: 0.1; PC4: 0.07; PC5: 0.07). f PC1 and PC2 g PC1 and PC3. h PC1 and PC5. PC4 did now show HFS dependent difference.
3/n
⚫ Under high-frequency stimulation (HFS), neural activity was altered in both a target-dependent and independent manner, showing that cerebellar signals contain task-related information.
22.03.2025 18:35
👍 1
🔁 0
💬 1
📌 0

c Single-session motor noise was estimated by calculating the mean absolute deviation (MAD) of maximal deviations during HFS trials and plotting against the motor noise calculated during the matching control sessions (n = 191). Darker dots (n = 91) indicate sessions where the motor noise under HFS was comparable to the motor noise level during the control trials (i.e., HFS/Control ratio >0.6 and <1.4). d Mean error sensitivity ±SEM calculated for a subset of adaptation sessions (n = 91), for which the pre-adaptation noise level was comparable during FF (blue) and FF-HFS (red) conditions (i.e., highlighted sessions in c).
2/n 🔍 Key Findings:
⚫ Cerebellar Block Impairs Adaptation: Blocking cerebellar outflow thanks to high-frequency stimulations (HFS) in the superior cerebellar peduncle significantly impairs force field (FF) adaptation, leading to increased motor noise and reduced error sensitivity.
22.03.2025 18:35
👍 1
🔁 0
💬 1
📌 0
Created a starter pack of neuroscience in/from Paris.
Let me know if you want to be added (the 'from' can include those not in Paris anymore) or just tap in if you want to know what we're talking about!
Regardless, please re-tweet!
go.bsky.app/3Zs9w5w
16.12.2024 20:45
👍 62
🔁 39
💬 28
📌 4
For the Blueskyers interested in #NeuroAI 🧠🤖,
I created a starter pack! Please comment on this if you are not on the list and working in this field 🙂
go.bsky.app/CscFTAr
17.10.2024 20:04
👍 120
🔁 51
💬 110
📌 5


