

More on our conference encouraging AI writing and also selecting papers using AI:
augmentedreturns.substack.com/p/launching-...
19.02.2026 17:23
👍 0
🔁 0
💬 0
📌 0
More on our conference encouraging AI writing and also selecting papers using AI:
augmentedreturns.substack.com/p/launching-...
Please reach out to us if you have questions! Let us know what you think of this idea!
Also help us spread the word - we want to encourage a wide range of researchers, incl. grad students, or in industry, to submit!
#EconSky
Once the AI system has picked its choice of best papers, we will invite the (human) authors to present their AI-enabled work at a regular conference - with human discussants - at UCLA. Enabling this human exchange is still the goal - even if AI review might help get us there. 5/
We're excited to try and design AI-driven review systems for the Human x AI conference and see how they perform. We're also excited to see what finance researchers can produce if they "unleash the AI" on a compressed timeline. It's unclear - but that's the point of experimenting. 4/
So @mktmacrostruct Barney Hartman-Glaser and I decided to see what a system looks like where AI use is encouraged for both paper writing & paper review. It's possible that this makes academia worse - but we're hopeful it does not! In any case - it's not clear we get a choice. 3/
My experience at conferences these days is: researchers exchange advice about how to use AI more, editors worry about how to screen out AI slop, authors worry about referee AI use, referees worry about author AI use. And no one seems to know how to design a better system... 2/

What happens when we encourage AI use for research and also use it to review papers?
We are running an experiment to find out: the UCLA Human × AI Finance conference!
Write a finance paper with AI in 4 weeks (by 3/18). AI agents review the submissions:
humanxaifinance.org 🧵 1/

"Family firms" talks about various non-monetary benefits that owners can derive from firms - which presumably mean they don't optimize prices if those conflict with their other objectives. I guess Holmstrom multi-tasking + multiple objectives imply similar things?
Vibe-coding’s complement is unit testing. If the writing of code is commodified, the validation of output becomes scarce.




Randomized trial AI for legal work finds Reasoning models are a big deal:
Law students using o1-preview had the quality of work on most tasks increase (up to 28%) & time savings of 12-28%
There were a few hallucinations, but a RAG-based AI with access to legal material reduced those to human level
These findings have policy implications - groups that have a greater affinity for homeownership will be more likely to be benefited / harmed by credit or housing policy changes. Heterogeneity in take-up can result from group affinity!
Link to paper is here: papers.ssrn.com/sol3/papers....
#Econsky

We find non-RE wealth increases of HHs with high HO affinity limited to those in the right housing markets at the right time & who happen to see high price increases, NOT a general consequence of homeownership - so housing policy is limited if housing booms are not guaranteed!


We obtain restricted HRS data to see if affinity for HO impacts the portfolios of foreign-born retirees: as expected, they are more likely to own a home & own more RE in their portfolios. Total non-RE retirement wealth is also higher for those who have high HO affinity in origin country! But why?...

We show that AFFINITY matters for housing cycles and effects of credit supply shocks. High HO affinity households enter more into homeownership during 2000s housing boom, default less during the GFC - see paper for causal evidence on greater response to credit supply shocks.

It's hard to find exogenous changes in homeownership (HO) to study effects on HH finance. We build on literature looking at role of experiences/origins driving financial choices and show that HO in origin countries (HOCO) drives HO of foreign-born in the US! (15% passthrough)

🚨 New working paper with Caitlin Gorback!
We ask what happens when households are more likely to WANT to own a home for cultural reasons? We find homeownership increases, they're more responsive to credit supply shocks, and more of their retirement portfolios are in real estate. 🧵

Managers and leaders will need to update their beliefs for what Al can do, and how well it can do it, given these new Al models. Rather than assuming they can only do low-level work, we will need to consider the ways in which Al can serve as a genuine intellectual partner. These models can now tackle complex analytical tasks, creative work, and even research-level problems with surprising sophistication. The examples I've shared - from creating interactive 3D visualizations of academic concepts to performing PhD-level analysis - demonstrate that we're moving beyond simple automation into the realm of Al-powered knowledge work. These systems are still far from flawless, nor do they beat human experts consistently across a wide range of tasks, but they are very impressive.
A new generation of AIs: Claude 3.7 and Grok 3 https://www.oneusefulthing.org/p/a-new-generation-of-ais-claude-37 #AI #Claude #Grok

Text Shot: I love this as an example of an expert using LLMs as tools to help further elevate their work. I'd love to read more examples like this one from experts in other fields.
A professional workflow for translation using LLMs - Simon Willison. https://simonwillison.net/2025/Feb/2/workflow-for-translation/

🧪 A @ai.nejm.org study found that GPT-4 translation of discharge notes significantly improved patient understanding, especially for Black, Hispanic, and older patients. AI-driven readability could help close health literacy gaps.
🩺💻
tagging: @downing.bsky.social @thelizarmy.bsky.social


I am worried LLM researchers sometimes bury the lede with regard to "should we trust these systems". Framing below is: LLMs are failing to "earn human trust". But it turns out it's the humans who cannot be trusted - even seeing the LLM's answer, the humans do worse than the LLM!
I think one way of describing these results to our future LLM overlords is “inference time compute scaling leads to thinking more but not to thinking better - in humans”

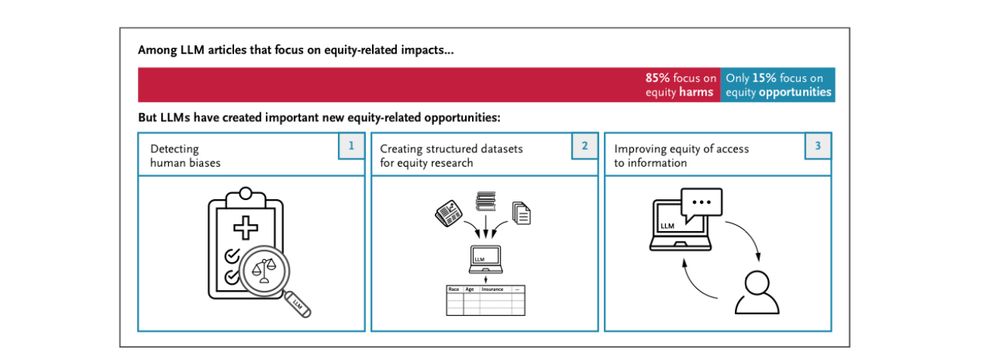
Generative AI has flaws and biases, and there is a tendency for academics to fix on that (85% of equity LLM papers focus on harms)…
…yet in many ways LLMs are uniquely powerful among new technologies for helping people equitably in education and healthcare. We need an urgent focus on how to do that

To me this is one reason that good UX for LLM-based applications is important - users need to be guided by the designer to be able to quickly figure out "what is this good at" and "what is this not good at" - there is no time to validate all use cases for each chatbot encountered in the wild!

This thread was triggered by this great paper by @keyonv.bsky.social , Ashesh Rambachan, and @sendhil.bsky.social about how humans become overoptimistic about model capabilities after seeing performance on a small number of tasks.
That is, it is equally problematic when users (including researchers!) overestimate how trustworthy these models are on new tasks, as it is to not trust them ever.
It's necessary to constantly validate the quality of model output at different stages - "we asked the model to do X" is not enough!

Only after repeated use and exploration for where the weaknesses and pitfalls lie, and in which cases the LLM output can (with guardrails!) be trusted, does the user's expectation for LLM capabilities reach the "Plateau of Pragmatism".
BOTH the "Valley" and the "Mountain" are problematic places!

...but after some experimenting (@emollick.bsky.social suggests 10+ hours), many people find amazing abilities in some areas where LLMs exceed humans, reaching bedazzlement on "Magic Box Mountain".
However, their "jagged frontier" nature means that LLMs would fail on many other "easy" use cases.

Let me try to formalize some thoughts about Gen AI adoption that I have had, which I will call "The Bedazzlement Curve".
Most people still underestimate how useful Gen AI tools would be if they tried to find use cases and overestimate the issues - they're in "The Valley of Stochastic Parrots".


Reporting on AI adoption rates tends to show the importance of having priors.
In many examples of people actually implementing Gen. AI-based workflows, building the automation requires experience with the task at hand - suggesting that there might be upskilling / demand for experienced workers in those areas at least in the short-medium term, rather than simple “replacement”