SDFT: Self-Distillation Enables Continual Learning
We’re really excited about self-distillation as a new paradigm for post-training.
Also check our work applying the same algorithm to offline data: self-distillation.github.io/SDFT
Here the baseline is SFT, not GRPO.
We show: Self-distillation enables continual learning.
29.01.2026 19:50
👍 3
🔁 0
💬 0
📌 0
Huge thanks to my amazing co-authors @rikelue.bsky.social, Lejs Behric, @antonbaumann.bsky.social, @marbaga.bsky.social, Daniel Marta, @idoh.bsky.social, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, @arkrause.bsky.social!!
(n/n)
29.01.2026 19:44
👍 1
🔁 0
💬 1
📌 0

One of my favorite experiments in the paper was seeing that SDPO can discover novel solutions to hard binary-reward problems.
SDPO allows learning even before seeing any reward! Simply by sequentially fixing "errors" as the model encounters them.
(7/n)
29.01.2026 19:41
👍 1
🔁 0
💬 1
📌 0

The key idea behind SDPO is to leverage a model's ability to learn in-context. We show that the gains of SDPO scale when scaling the base model.
In other words: Better models → better retrospection in SDPO → better models
(6/n)
29.01.2026 19:41
👍 1
🔁 0
💬 1
📌 0

RLVR doesn't just lead to poor credit assignment, it learns reasoning that is inefficient! RLVR's learned reasoning style is verbose and often circular.
SDPO demonstrates that effective reasoning does not have to be verbose!
How? The self-teacher penalizes useless tokens.
(5/n)
29.01.2026 19:40
👍 1
🔁 0
💬 1
📌 0

One of our results: We train Olmo3-7B-Instruct on a new task.
SDPO achieves GRPOs 5h accuracy in 30min wall-clock time and SDPO converges to 20%pts higher accuracy.
Also, SDPO learns more concise reasoning (see below).
(4/n)
29.01.2026 19:40
👍 1
🔁 0
💬 1
📌 0

Why does this work? When conditioned on rich feedback, the model retrospectively evaluates its initial attempt. Anything that seems wrong in hindsight is discouraged. Anything that was good is encouraged.
This leads to interesting patterns of advantages 👇
(3/n)
29.01.2026 19:40
👍 1
🔁 0
💬 1
📌 0

Introducing Self-Distillation Policy Optimization (SDPO).
Key insight: Putting environment feedback (like runtime errors) and successful attempts in-context, turning the model into its own teacher.
Bonus: Virtually same runtime as GRPO!
(2/n)
29.01.2026 19:40
👍 2
🔁 1
💬 1
📌 0

Training LLMs with verifiable rewards uses 1bit signal per generated response. This hides why the model failed.
Today, we introduce a simple algorithm that enables the model to learn from any rich feedback!
And then turns it into dense supervision.
(1/n)
29.01.2026 19:38
👍 10
🔁 3
💬 1
📌 1

On my way to Montreal for COLM. Let me know if you’re also coming! I’d be very happy to catch up!
We present our poster at #1013 in the Wednesday morning session.
Joint work with the amazing Ryo Bertolissi, @idoh.bsky.social, @arkrause.bsky.social.
06.10.2025 10:52
👍 11
🔁 1
💬 0
📌 0
Paper: arxiv.org/pdf/2410.05026
Joint work with the amazing @marbaga.bsky.social, @gmartius.bsky.social, @arkrause.bsky.social
14.07.2025 19:38
👍 0
🔁 0
💬 0
📌 0
We propose an algorithm that does this by actively maximizing expected information gain of the demonstrations, with a couple of tricks to estimate this quantity and mitigate forgetting.
Interestingly, this solution is viable even without any information about pre-training!
14.07.2025 19:35
👍 0
🔁 0
💬 1
📌 0

In our ICML paper, we study fine-tuning a generalist policy for multiple tasks. We ask, provided a pre-trained policy, how can we maximize multi-task performance with a minimal number of additional demonstrations?
📌 We are presenting a possible solution on Wed, 11am to 1.30pm at B2-B3 W-609!
14.07.2025 19:35
👍 11
🔁 4
💬 1
📌 0

Our method significantly improves accuracy (measured as perplexity) for large language models and achieves a new state-of-the-art on the Pile benchmark.
If you're interested in test-time training or active learning, come chat with me at our poster session!
21.04.2025 14:40
👍 2
🔁 0
💬 0
📌 0

We introduce SIFT, a novel data selection algorithm for test-time training of language models. Unlike traditional nearest neighbor methods, SIFT uses uncertainty estimates to select maximally informative data, balancing relevance & diversity.
21.04.2025 14:40
👍 2
🔁 0
💬 1
📌 0
Paper: arxiv.org/pdf/2410.08020
21.04.2025 14:38
👍 0
🔁 0
💬 1
📌 0

✨ Very excited to share that our work "Efficiently Learning at Test-Time: Active Fine-Tuning of LLMs" will be presented at ICLR! ✨
🗓️ Wednesday, April 23rd, 7:00–9:30 p.m. PDT
📍 Hall 3 + Hall 2B #257
Joint work with my fantastic collaborators Sascha Bongni,
@idoh.bsky.social, @arkrause.bsky.social
21.04.2025 14:37
👍 16
🔁 1
💬 1
📌 0
We've released our lecture notes for the course Probabilistic AI at ETH Zurich, covering uncertainty in ML and its importance for sequential decision making. Thanks a lot to @jonhue.bsky.social for his amazing effort and to everyone who contributed! We hope this resource is useful to you!
17.02.2025 07:19
👍 61
🔁 10
💬 1
📌 0
Unfortunately not as of now. We may also release Jupyter notebooks in the future, but this may take some time.
12.02.2025 22:25
👍 0
🔁 0
💬 1
📌 0
I'm glad you find this resource useful Maximilian!
11.02.2025 15:26
👍 1
🔁 0
💬 0
📌 0
Noted. Thanks for the suggestion!
11.02.2025 09:01
👍 1
🔁 0
💬 0
📌 0
Very glad to hear that they’ve been useful to you! :)
11.02.2025 08:37
👍 2
🔁 0
💬 1
📌 0



table of contents:
11.02.2025 08:35
👍 4
🔁 0
💬 1
📌 0
Huge thanks to the countless people that helped in the process of bringing this resource together!
11.02.2025 08:20
👍 2
🔁 0
💬 1
📌 0


I'm very excited to share notes on Probabilistic AI that I have been writing with @arkrause.bsky.social 🥳
arxiv.org/pdf/2502.05244
These notes aim to give a graduate-level introduction to probabilistic ML + sequential decision-making.
I'm super glad to be able to share them with all of you now!
11.02.2025 08:19
👍 120
🔁 25
💬 3
📌 3

Thou Shalt Not Overfit
Venting my spleen about the persistent inanity about overfitting.
Overfitting, as it is colloquially described in data science and machine learning, doesn’t exist. www.argmin.net/p/thou-shalt...
30.01.2025 15:35
👍 70
🔁 12
💬 11
📌 5
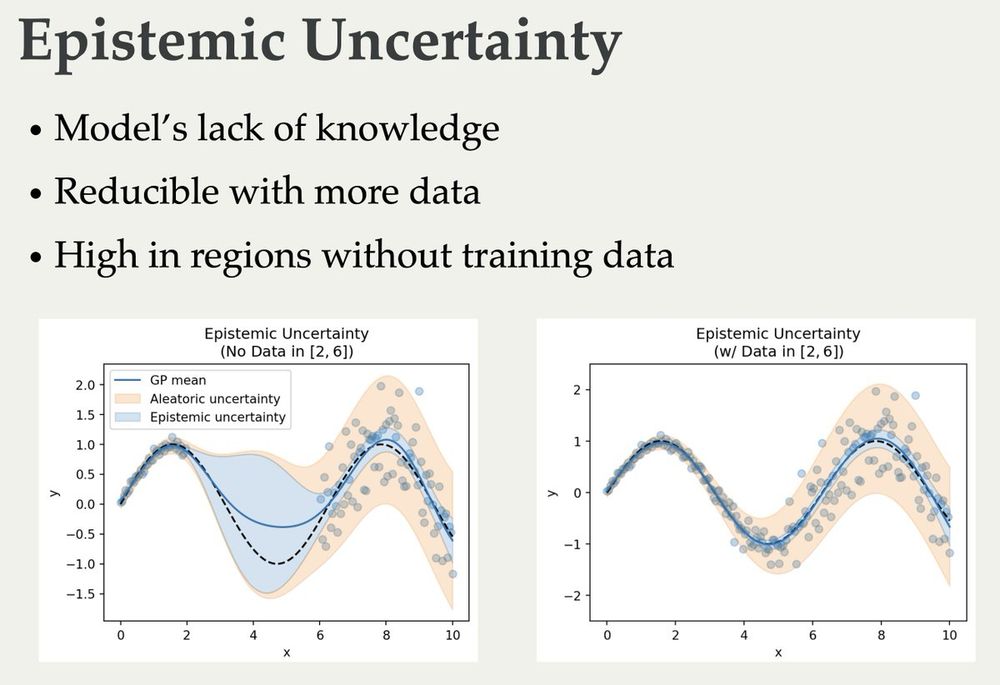
The slides for my lectures on (Bayesian) Active Learning, Information Theory, and Uncertainty are online now 🥳 They cover quite a bit from basic information theory to some recent papers:
blackhc.github.io/balitu/
and I'll try to add proper course notes over time 🤗
17.12.2024 06:50
👍 177
🔁 28
💬 3
📌 0
Preprint: arxiv.org/pdf/2410.08020
13.12.2024 18:33
👍 2
🔁 0
💬 1
📌 0
Tomorrow I’ll be presenting our recent work on improving LLMs via local transductive learning in the FITML workshop at NeurIPS.
Join us for our ✨oral✨ at 10:30am in east exhibition hall A.
Joint work with my fantastic collaborators Sascha Bongni, @idoh.bsky.social, @arkrause.bsky.social
13.12.2024 18:32
👍 5
🔁 4
💬 1
📌 0

