Oh, so that’s why “sound on sound” magazine insist on taking a photo of the prize winner with their new studio additions.
04.02.2026 09:18
👍 2
🔁 0
💬 0
📌 0
Oh, so that’s why “sound on sound” magazine insist on taking a photo of the prize winner with their new studio additions.
4,000 now? 😮
Exciting step for you, all the best.
Today’s news headlines, clustered.

Spotting significant terms was something I added to elasticsearch. Can we do it more cheaply in the browser with similar quality? It looks like the answer is "yes" youtu.be/Te_N8qveCKY

Before it got too hot today 🥵

My talk on “emergent facets” at this week’s Search and AI Meetup www.youtube.com/watch?v=U1RG...

Today was a good day
My recent elasticon talk is up. Play with the updated demos at QRy.codes too.
Looking forward to presenting “fuzzy facets” using binary vector clustering at this week’s elasticon London www.elastic.co/events/elast...
Just started with OpenRouter and it makes me wish there was an equivalent for streaming tv. One login account, one stack of credits to pay for and then pay-as-you-go consumption of any service.

Blue skies all this week ❤️
Congrats, David!
I knew this day would come eventually 😀
Wordle 1,290 1/6
🟩🟩🟩🟩🟩
A little #Insta360 footage from today
Perhaps an obvious discovery but I find woodworking is just like developing efficient search algos - you need to use a combination of coarse and fine tools (respectively for efficiency in removing what you don’t need and producing quality results).
True that a lot of apps don’t need distributed but the other big consideration is opening up Lucene to non-Java apps with client libs for Python, JavaScript, ruby etc etc.
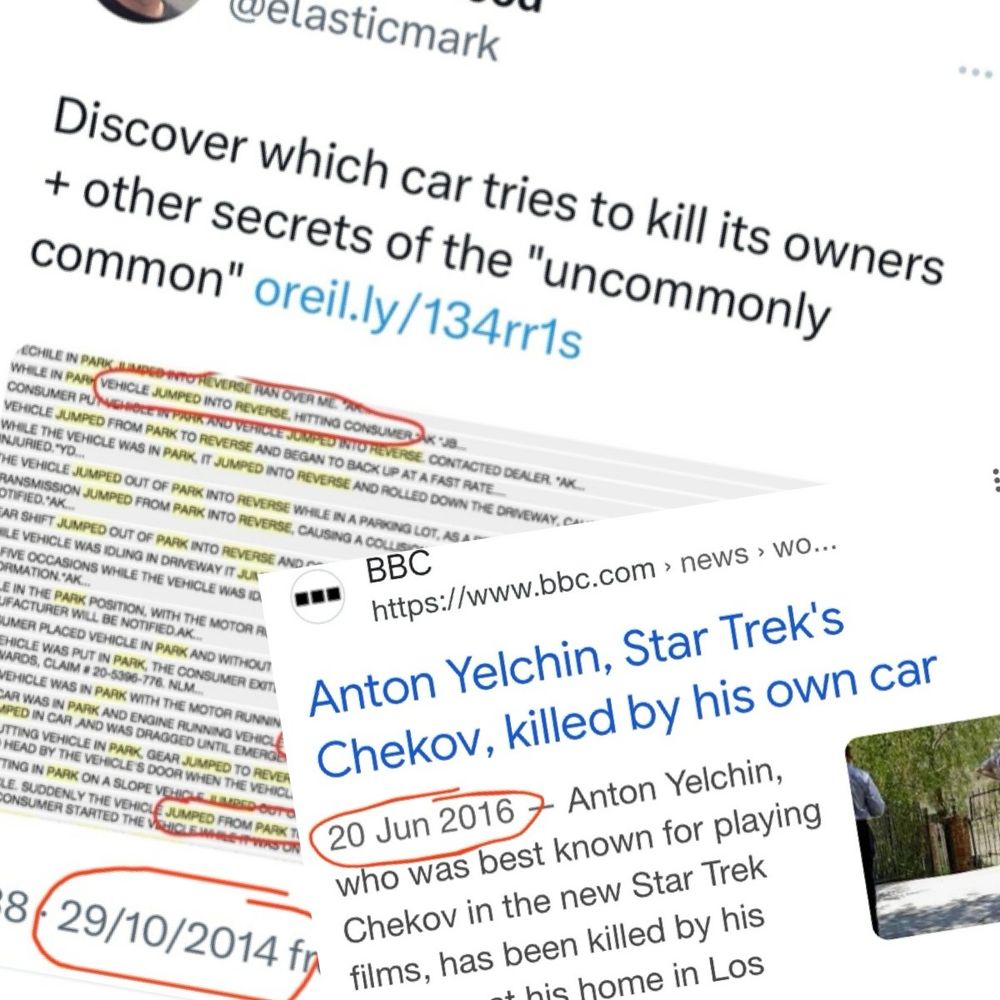
One from my Twitter archive: highlighting Jeep Cherokees had “jumped”, “park” and “reverse” as significant keywords in fault reports. 2 years later a Hollywood star was killed as a result of this fault.
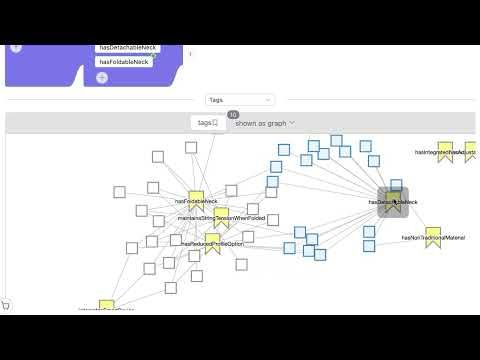
It follows a principle of mine - plain text syntaxes like regex or Lucene query string are confusing for end users. Use them for quick input by all means, but a graphical editor for a more structured data format can help remove the problems inherent with plain text syntax.

Nice. I proposed a new feature for elasticsearch relating to help solve some regex pain some time ago github.com/elastic/elas...

Seems an unnecessarily cruel way to go about this.
How about indexing a fields token count using the “token_count” field type?
You’d need to run a query past the _analyze api to get the number of query tokens first but your phrase query could then sit alongside another mandatory clause with the token count

When the content being searched isn’t human-generated eg log files there is no consensus on where words begin and end. Regex type searches need to match *anywhere* in this content. See use of ngrams here: www.elastic.co/blog/find-st...
Hey there, Mr Blue (Sky).
I’m fed up with the Twitter cesspit. I’ll probably be posting about my post-elastic dabblings like qry.codes and other search stuff here.