Paper: arxiv.org/pdf/2505.11080
Code: github.com/lilakk/BLEUB... (coming soon)
Work done with the amazing @yekyung.bsky.social from UMD, Michael Krumdick from Kensho, Amir Zadeh and Chuan Li from LambdaAI ,
@chriswtanner.bsky.social from Kensho, and @miyyer.bsky.social from UMD
20.05.2025 16:25
👍 0
🔁 0
💬 0
📌 0

Beyond benchmarks, human annotators rate BLEUBERI outputs as comparable to those from GRPO-RM models.
20.05.2025 16:25
👍 0
🔁 0
💬 1
📌 0

Qualitatively, BLEUBERI models produce more factually grounded outputs, as measured by VeriScore on three diverse datasets. VeriScore extracts verifiable claims from responses and checks each one against Google Search.
20.05.2025 16:25
👍 0
🔁 0
💬 1
📌 0

The surprising effectiveness of BLEU extends to training. BLEUBERI first selects 5K low-BLEU examples, then trains LLMs with GRPO using BLEU as the reward. BLEUBERI models are competitive as those trained with GRPO-RM (8B) and SFT across 4 benchmarks.
20.05.2025 16:25
👍 0
🔁 0
💬 1
📌 0

When BLEU agrees with humans on a pair of model outputs, what n-grams contribute to this decision? Below is an example where it captures both format (the “Ukrainian” and “English” headers) and factuality (the number 6.1).
20.05.2025 16:25
👍 0
🔁 0
💬 1
📌 0

BLEU is often dismissed for weak human correlation in generation tasks. But on general instruction following, using BLEU to rank pairs of Chatbot Arena outputs—scored against references from strong LLMs—matches 8B & 27B reward models in human agreement, especially with more refs.
20.05.2025 16:25
👍 0
🔁 0
💬 1
📌 0

BLEU is widely used for machine translation (MT) eval. Given a reference and a generation, it computes modified n-gram precision (1–4 grams) and applies a brevity penalty to penalize short outputs. If given multiple references, it takes the max match per n-gram.
20.05.2025 16:25
👍 0
🔁 0
💬 1
📌 0
🤔 Can simple string-matching metrics like BLEU rival reward models for LLM alignment?
🔍 We show that given access to a reference, BLEU can match reward models in human preference agreement, and even train LLMs competitively with them using GRPO.
🫐 Introducing BLEUBERI:
20.05.2025 16:25
👍 5
🔁 1
💬 1
📌 1
🕵️♀️ agents are strong on many tasks, but are they good at interacting with the web? 🧸our BEARCUBS benchmark shows that they struggle on interactive tasks that seem trivial to humans! 📄 check out the paper for how to build robust evaluations & directions for future agent research
12.03.2025 14:40
👍 2
🔁 0
💬 0
📌 0

Is the needle-in-a-haystack test still meaningful given the giant green heatmaps in modern LLM papers?
We create ONERULER 💍, a multilingual long-context benchmark that allows for nonexistent needles. Turns out NIAH isn't so easy after all!
Our analysis across 26 languages 🧵👇
05.03.2025 17:06
👍 14
🔁 5
💬 1
📌 3
current models struggle with complex long-range reasoning tasks 📚 how can we reliably create synthetic training data?
💽 check out CLIPPER, a pipeline that generates data conditioning on compressed forms of long input documents!
21.02.2025 16:30
👍 8
🔁 0
💬 0
📌 0

People often claim they know when ChatGPT wrote something, but are they as accurate as they think?
Turns out that while general population is unreliable, those who frequently use ChatGPT for writing tasks can spot even "humanized" AI-generated text with near-perfect accuracy 🎯
28.01.2025 14:55
👍 189
🔁 66
💬 10
📌 19

Finally, a Replacement for BERT: Introducing ModernBERT
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
Great blog post (by a 15-author team!) on their release of ModernBERT, the continuing relevance of encoder-only models, and how they relate to, say, GPT-4/llama. Accessible enough that I might use this as an undergrad reading.
19.12.2024 19:11
👍 75
🔁 19
💬 1
📌 1

🚨I too am on the job market‼️🤯
I'm searching for faculty positions/postdocs in multilingual/multicultural NLP, vision+language models, and eval for genAI!
I'll be at #NeurIPS2024 presenting our work on meta-evaluation for text-to-image faithfulness! Let's chat there!
Papers in🧵, see more: saxon.me
06.12.2024 01:44
👍 49
🔁 9
💬 1
📌 2

😵 fish washed up on the shore of walden pond
🐠 what monday feels like..
02.12.2024 23:46
👍 8
🔁 0
💬 0
📌 0
private closed-source evals are the future 🫣
26.11.2024 20:37
👍 2
🔁 0
💬 0
📌 0
Tommy Guerrero Best Of | 最高の
YouTube video by partedoparque
www.youtube.com/watch?v=afQT...
25.11.2024 23:17
👍 2
🔁 0
💬 0
📌 0

arxiv-utils Chrome web store
i knew something like this had to exist but why did i only discover it now?? no more suffering from looking at my 10+ open arxiv tabs not knowing which one is which...
25.11.2024 21:22
👍 27
🔁 3
💬 0
📌 1
🙋🏻♀️
23.11.2024 22:19
👍 1
🔁 0
💬 0
📌 0
I noticed a lot of starter packs skewed towards faculty/industry, so I made one of just NLP & ML students: go.bsky.app/vju2ux
Students do different research, go on the job market, and recruit other students. Ping me and I'll add you!
23.11.2024 19:54
👍 176
🔁 54
💬 101
📌 4
i also got 10/10! the ones that rhyme too well feel very AI to me..
21.11.2024 16:51
👍 2
🔁 0
💬 1
📌 0
such a creative way of using long-context models! this sounds like a super hard evaluation task, but gemini is already so good at it...
21.11.2024 15:04
👍 5
🔁 0
💬 1
📌 0
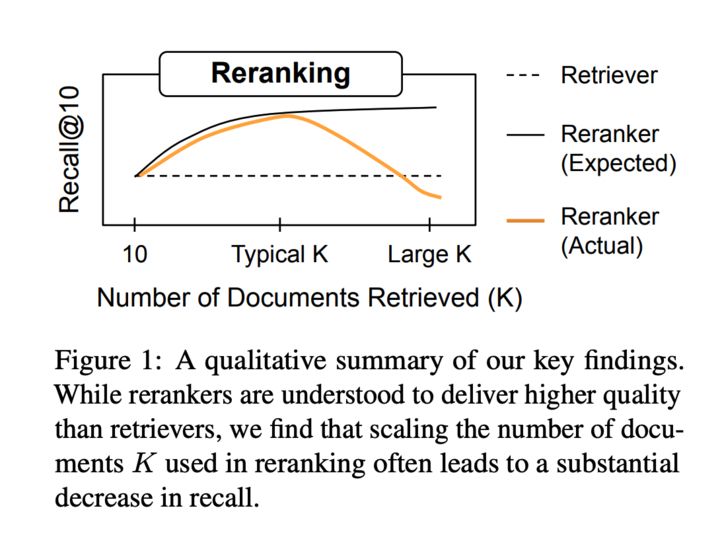
A plot showing that reranking improves recall as we increase the number of reranked docs, but with increasing docs we diminishing returns and eventually a performance dip.
Mat is not on 🦋—posting on his behalf!
It's time to revisit common assumptions in IR! Embeddings have improved drastically, but mainstream IR evals have stagnated since MSMARCO + BEIR.
We ask: on private or tricky IR tasks, are rerankers better? Surely, reranking many docs is best?
20.11.2024 19:44
👍 81
🔁 23
💬 4
📌 5
llms are now training humans with data from their distribution
19.11.2024 03:47
👍 5
🔁 0
💬 1
📌 0
The soul-searching journey for figuring out what research area is right for you is tricky since so many papers are cool. I tell my early career students that they should try to differentiate papers that they'd like to read 📖, implement 🔨, *and* write 📝 from papers that they'd only like to read 📖.
18.11.2024 23:32
👍 67
🔁 11
💬 4
📌 0

airbnb >>> hotel for conferences #EMNLP2024
17.11.2024 01:28
👍 4
🔁 0
💬 0
📌 0
Abhilasha Ravichander - Home
✨I am on the faculty job market in the 2024-2025 cycle!✨
My research centers on advancing Responsible AI, specifically enhancing factuality, robustness, and transparency in AI systems.
If you have relevant positions, let me know! lasharavichander.github.io Please share/RT!
11.11.2024 14:23
👍 51
🔁 22
💬 2
📌 1





