More on this idea here: metr.org/blog/2024-11...
07.03.2026 03:57
👍 4
🔁 0
💬 0
📌 0

@chris
evals accelerationist, Head of Policy at METR, working hard on responsible scaling policies Check out my artisanal hand-crafted "AI Bluesky" starter pack here: https://bsky.app/starter-pack/chris.bsky.social/3lbefurb2xh2u

Worth reading this in full. I come in skeptical, but this basically is a claim that an AI system at Alibaba attempted autonomous replication without human intervention.
This excerpt was found and highlighted by Alexander Long. Full paper here: arxiv.org/abs/2512.24873

We’re correcting a mistake in our modeling that inflated recent 50%-time horizons by 10-20% (and reduced 80%-horizons). We inappropriately penalized steepness in task-length→success curve fits. This most affects the oldest and newest models, whose fits are less data-constrained.

Since early 2025, we've been studying how AI tools impact productivity among developers. Previously, we found a 20% slowdown. That finding is now outdated. Speedups now seem likely, but changes in developer behavior make our new results unreliable. We’re working to address this.
Our team is stretched thin at the moment!
To continue upper-bounding the autonomy of AI agents, and developing evaluations for monitoring AI systems and their propensity to subvert human control, we need more great engineering and research staff. Please apply below or DM me!
Groundhog Day is a very METR-y holiday. Small animal emerges from a cave for only a moment, shares a forecast about timelines that's somewhat difficult to interpret, and then retreats into his cave for another year.

Today we published a critique of @metr.org’s time-horizon methodology by one of the paper’s lead authors, Thomas Kwa
Link: metr.org/notes/2026-0...
Maybe this isn't what people mean by "permanent underclass", maybe they don't imagine it involves any subjugation or won't be unpleasant.
That isn't the impression their urgency to evade this "underclass" gives.
If "escaping the permanent underclass" is the explicit motivation, then this isn't that. The explicit belief here is that some people will be subjugated, and the speaker needs to make sure they aren't one of the subjugated.
Obviously, it's fine and great to build one's personal wealth in ways that create consumer surplus and increased quality of life for everyone, and even to only accomplish the latter unthinkingly while e.g. building an amazing business.
I do occasionally now hear tech/finance people sincerely say that they need to focus on making more money to "escape the permanent underclass"
It's important to emphasize how selfish orienting one's life around that goal is, rather than improving the median outcome for everyone
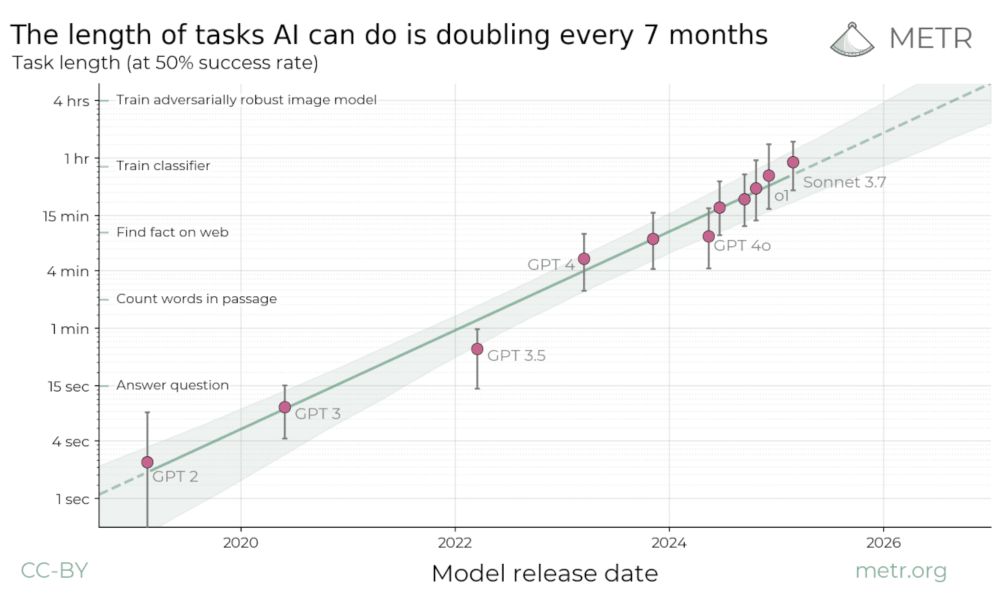
The full website lets you toggle and see the task-horizon at 80% success rate as well. The resolution we can observe confidently is very low at pass rates like 95%
Full site: metr.org/blog/2025-03...
Original paper explaining: arxiv.org/abs/2503.14499
We first characterize the difficulty of the tasks in our suite by seeing how long they take experienced human developers/engineers/researchers. We then sort the tasks into buckets based on how long they take humans. Grok 4 gets 50% success on the ~1hr50min part of the task difficulty distribution
Oh I also should clarify that we have many more than 2 projects going in parallel at any given time hahahaha, these two were just similar
Oh I also should clarify that we have many more than 2 projects going in parallel at any given time time, for what it’s worth
To be clear: The other project was very nascent, and would’ve been far less quantitative/experimental, more like an index of developer anecdotes. To my knowledge the RCT was not formally pre-registered, but I would want to check with the people on our team who worked on it
For me, the biggest upshot of this work, at the moment, is that the most obvious and straightforward ways of assessing AI R&D acceleration from access to AI, like "just survey people" or "monitor the vibes in your AI lab" probably won't work, or will badly misfire.
METR a few months ago had two projects going in parallel: a project experimenting with AI researcher interviews to track degree of AI R&D acceleration/delegation, and this project.
When the results started coming back from this project, we put the survey-only project on ice.

At METR, we’ve seen increasingly sophisticated examples of “reward hacking” on our tasks: models trying to subvert or exploit the environment or scoring code to obtain a higher score. In a new post, we discuss this phenomenon and share some especially crafty instances we’ve seen.
personal update: today is my last day with the Bluesky team!
this is bittersweet news to share, but the great thing about an open network is you never really have to leave. I’ll be rooting for Bluesky and atproto from the outside 🫡💙
In particular, the amount of influence and power that depends on the outcomes of these debates, without any of these people really being in the trenches of politics or business, feels very monastic
You have these monks and scholars hidden away in a sort of monastery, and the law of the land hangs on their calm debates about the correct way to interpret our secular scripture
I spent a few days at Yale Law, while also listening to Sam Harris’s interview with Tom Holland about his book “Dominion”, and it’s striking how similar the role and vibe of the American judiciary is to a kind of secular priesthood. Robes, scholars interpreting sacred texts

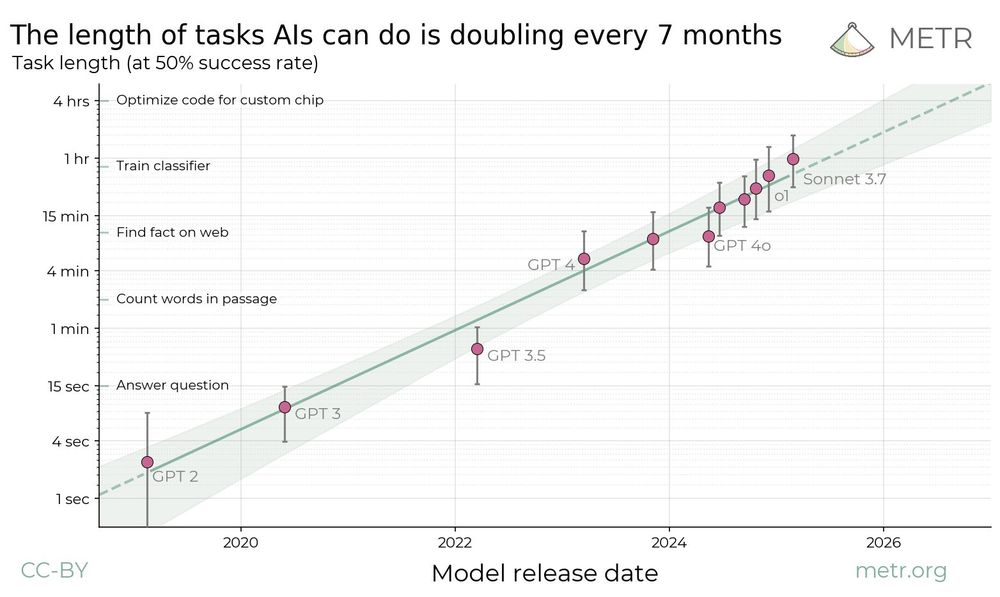
When will AI systems be able to carry out long projects independently?
In new research, we find a kind of “Moore’s Law for AI agents”: the length of tasks that AIs can do is doubling about every 7 months.
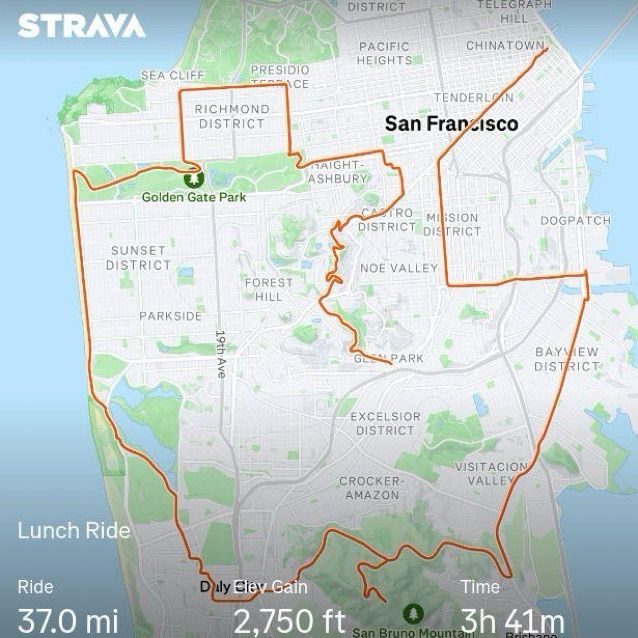
Bought a new bike this weekend :(
Taking science fiction seriously - thinking with effort about which ideas from sci-fi could become real soon and why and which couldn’t - has been so useful to me that it feels something like a core value
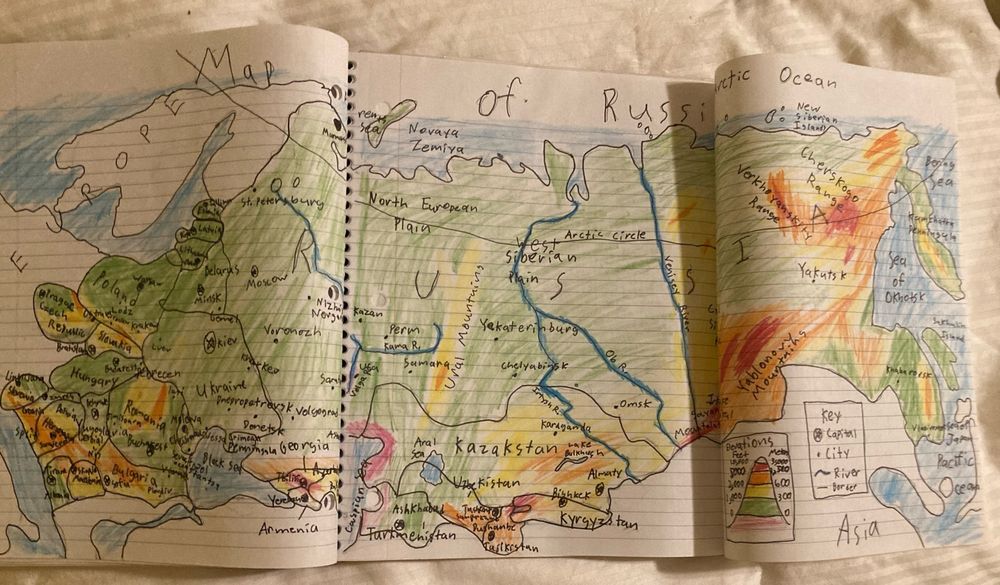
Look at this extremely expansive definition of Russia’s territory on my hand-drawn 7th grade map
