Summary: Practical nets do not approach kernel limits. Instead, they converge to a Feature Learning Limit.
This offers a new lens: Empirical quirks (like aggressive LR scaling) are not mere finite-width artefacts - they are faithful reflections of the true scaling limit. (9/10)
03.12.2025 17:37
👍 1
🔁 0
💬 1
📌 0
Early experiments suggest DL components like Adam & Norm layers also enable Controlled Divergence regimes.
Caveat: Controlled Divergence can still cause overconfidence and floating-point instabilities (precision failure) at scale! (8/10)
03.12.2025 17:37
👍 1
🔁 0
💬 1
📌 0

This may explain the practical success of CE over MSE!
CE admits larger LRs → richer feature learning. MSE is restricted to Lazy regime.
Validation: Under µP (where both losses admit feature learning), performance gaps vanish. MSE even seems to have an edge at scale! (7/10)
03.12.2025 17:37
👍 1
🔁 0
💬 1
📌 0

At the edge of this regime (where η ∝ 1/√m), there exists a well-defined infinite-width limit where feature learning persists in all hidden layers.
This Feature Learning Limit closely matches the behavior of optimally tuned finite-width networks under CE loss. (6/10)
03.12.2025 17:37
👍 1
🔁 0
💬 1
📌 0
In the Controlled Divergence regime, network outputs diverge (saturating to one-hot). Yet, all the other dynamical quantities such as the activations and gradients remain stable throughout training.
This regime, however, does not exist under MSE. (5/10)
03.12.2025 17:37
👍 1
🔁 0
💬 1
📌 0

We resolve this via a fine-grained analysis of the regime previously considered unstable (and therefore uninteresting).
Under CE loss, we find this regime comprises two distinct sub-regimes: A Catastrophically Unstable Regime and A benign Controlled Divergence regime. (4/10)
03.12.2025 17:37
👍 1
🔁 0
💬 1
📌 0

We find this discrepancy persists even accounting for finite-width effects due to Catapult/EOS, Large Depth, Alignment Violations.
In fact, infinite-width alignment predictions hold robustly when measured with sufficient granularity.
So what explains this discrepancy? (3/10)
03.12.2025 17:37
👍 2
🔁 0
💬 1
📌 0

Most nets use He/Lecun init with single LR η. As width m→∞, theory says
η∈O(1/m)⟹Kernel; η∈ω(1/m)⟹Unstable.
Thus max stable LR∝1/m.
Practice violates this. Optimal LRs are larger (e.g.∝1/√m) & models admit feature learning; contradicts kernel predictions. Why? (2/10)
03.12.2025 17:37
👍 1
🔁 0
💬 1
📌 0
Under He/Lecun inits, theory implies Kernel OR Unstable regimes as width→∞. Discrepancies (e.g. feature learning) are seen as finite width effects.
Our #NeurIPS2025 spotlight refutes this: practical nets do not converge to kernel limits; Feature learning persists as width→∞🧵
03.12.2025 17:37
👍 7
🔁 2
💬 1
📌 0
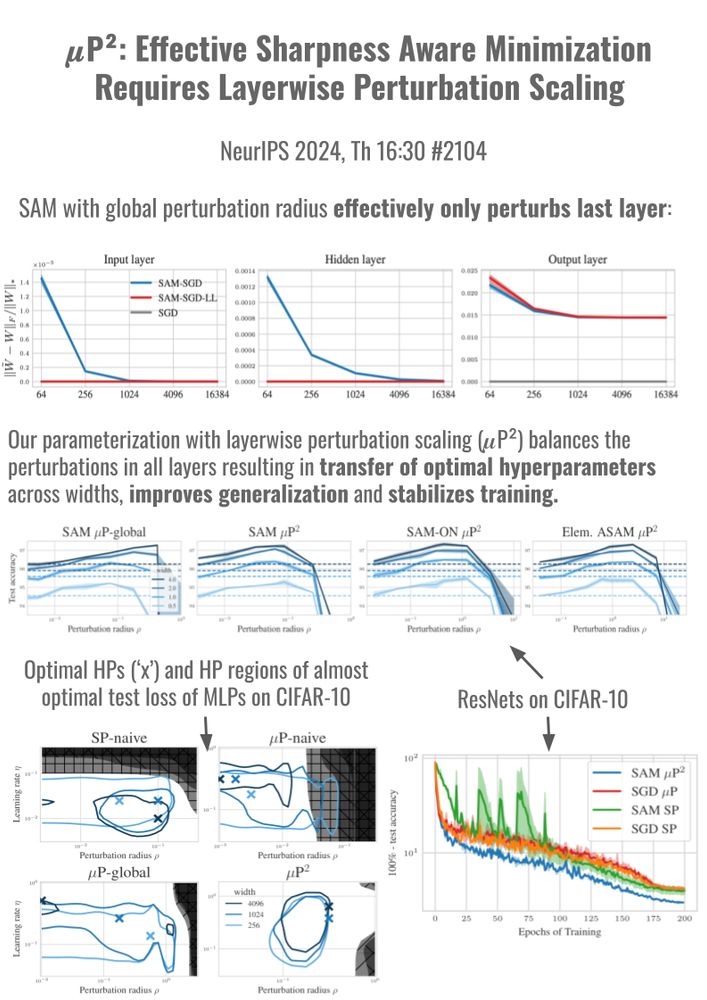
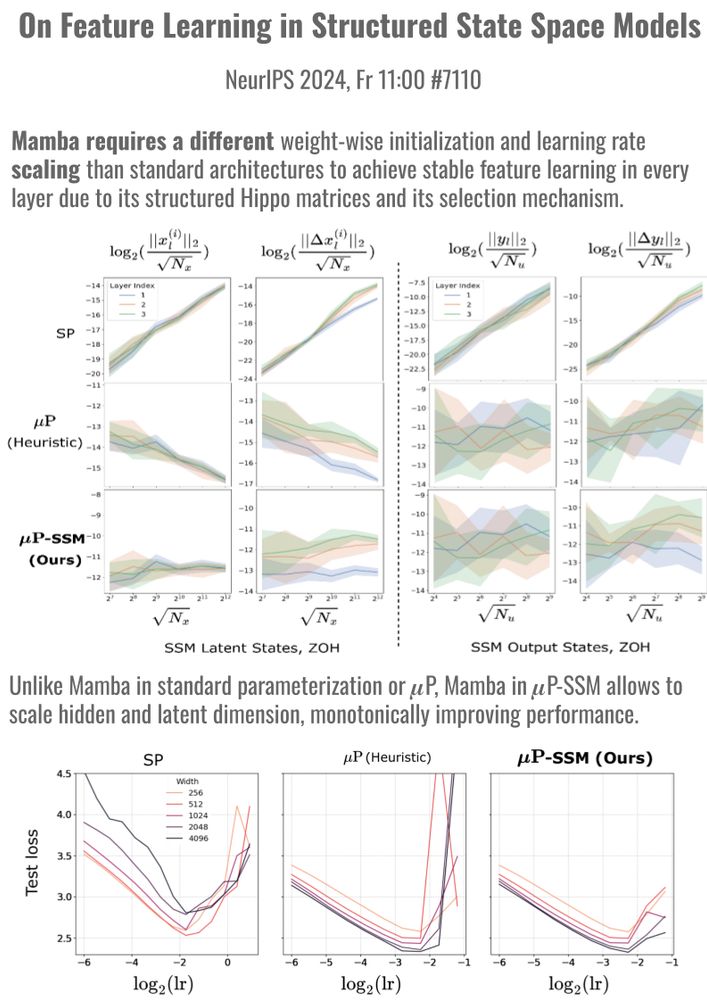
Stable model scaling with width-independent dynamics?
Thrilled to present 2 papers at #NeurIPS 🎉 that study width-scaling in Sharpness Aware Minimization (SAM) (Th 16:30, #2104) and in Mamba (Fr 11, #7110). Our scaling rules stabilize training and transfer optimal hyperparams across scales.
🧵 1/10
10.12.2024 07:08
👍 21
🔁 5
💬 1
📌 0
Could you please add me to the list?
26.11.2024 09:15
👍 1
🔁 0
💬 1
📌 0

