
Thanks for sharing!
I put care and love into the cover, creating it in QGIS and Illustrator to showcase my beloved Zaragoza
20.01.2026 12:41
👍 6
🔁 1
💬 0
📌 0
Thanks for sharing!
I put care and love into the cover, creating it in QGIS and Illustrator to showcase my beloved Zaragoza
One concern that I have as an AI researcher when publishing code is that it can potentially be used in dual-use applications.
To solve this, we propose Civil Software Licenses. They prevent dual-use while being minimal in the restrictions they impose:
civil-software-licenses.github.io
Presenting today at #CVPR poster 81.
Code is available at github.com/nianticlabs/...
Want to try it on an iPhone video? On Android? On any other sequence you have? We got you covered. Check the repo.
Presenting it now at #CVPR
Happy to be one of them
We focused on depth from videos and as you pointed we didn't train on datasets with different captures per scene.

Check the website: nianticlabs.github.io/mvsanywhere/
And the paper: arxiv.org/pdf/2503.22430
Code coming soon!
Great work with @mohamedsayed.bsky.social @mdfirman.bsky.social @guiggh.bsky.social D. Turmukhambetov @jcivera.bsky.social @oisinmacaodha.bsky.social @gbrostow.bsky.social J. Watson
💡Use case:
We show how the accurate and robust depths from MVSAnywhere serve to regularize gaussian splats, obtaining much cleaner scene reconstructions.
As MVSAnywhere is agnostic to the scene scale, this is plug-and-play for your splats!

Quantitative results of MVSAnywhere
🏆Results:
MVSAnywhere achieves state-of-the-art results on the Robust Multi-View Depth Benchmark, showing its strong generalization performance.
🧩Challenge: Varying Depth Scales & Unknown Ranges
🔹Most models require a known depth range to estimate the cost volume.
✅MVSAnywhere estimates an initial range based on camera scale and setup and refines it. It predicts at the same scale as the input cameras!

Qualitative results of mvsanywhere
🧩Challenge: Domain Generalization
🔹Previous models struggle across different domains ( indoor🏠 vs outdoor🏞️).
✅MVSAnywhere uses a transformer architecture and is trained on a large array of varied synthetic datasets

MVSAnywhere works with dynamic objects and casually captured videos.
🧩Challenge: Robustness to casually captured videos
🔹MVS methods completely rely on the matches of the cost volume (not working for low overlap & dynamic)
✅MVSAnywhere successfully combines strong single-view image priors with multi-view information from our cost volume
🔍Looking for a multi-view depth method that just works?
We're excited to share MVSAnywhere, which we will present at #CVPR2025. MVSAnywhere produces sharp depths, generalizes and is robust to all kind of scenes, and it's scale agnostic.
More info:
nianticlabs.github.io/mvsanywhere/
MASt3R-SLAM code release!
github.com/rmurai0610/M...
Try it out on videos or with a live camera
Work with
@ericdexheimer.bsky.social*,
@ajdavison.bsky.social (*Equal Contribution)

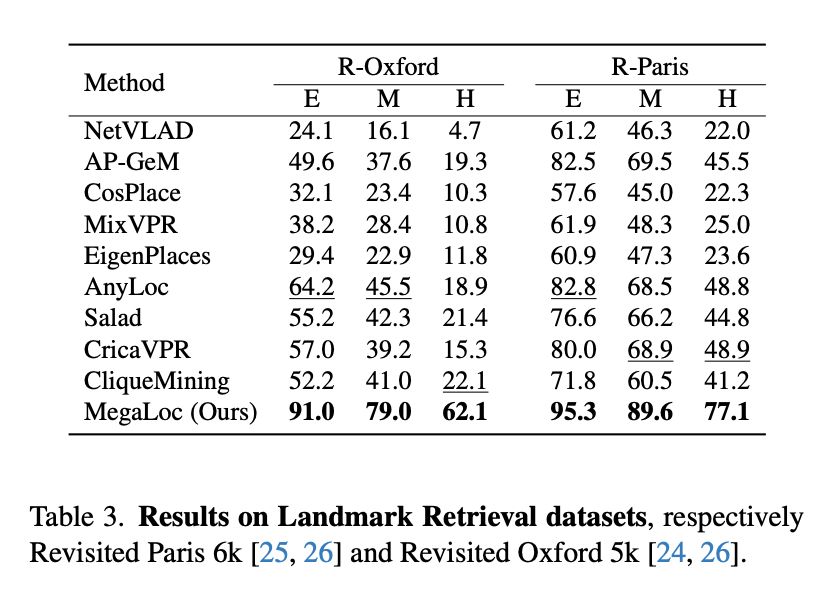

MegaLoc: One Retrieval to Place Them All
@berton-gabri.bsky.social Carlo Masone
tl;dr: DINOv2-SALAD, trained on all available VPR datasets works very well.
Code should at github.com/gmberton/Meg..., but not yet
arxiv.org/abs/2502.17237


