That's interesting, intuitively I'd think that you need a certain document length for LDA to reliably capture repeated word co-occurrences as signals for underlying topics... It would be quite useful to do a systematic comparison that doesn't have all the flaws of the above mentioned paper!
09.12.2025 12:21
👍 0
🔁 0
💬 1
📌 0
Also, I've never quite seen the value of stemming for topic modeling, but I'd argue that preprocessing in general is an important part of any method. That's why I wouldn't necessarily copy every preprocessing step when comparing methods, especially when the latter are quite different.
09.12.2025 09:01
👍 1
🔁 0
💬 1
📌 0
I suspect that a good number of citations stem from the fact that the paper "confirms" a common experience in the CSS community: that embedding-based topic models tend to produce more interpretable topics than LDA _on very short texts_.
09.12.2025 08:56
👍 2
🔁 0
💬 3
📌 0
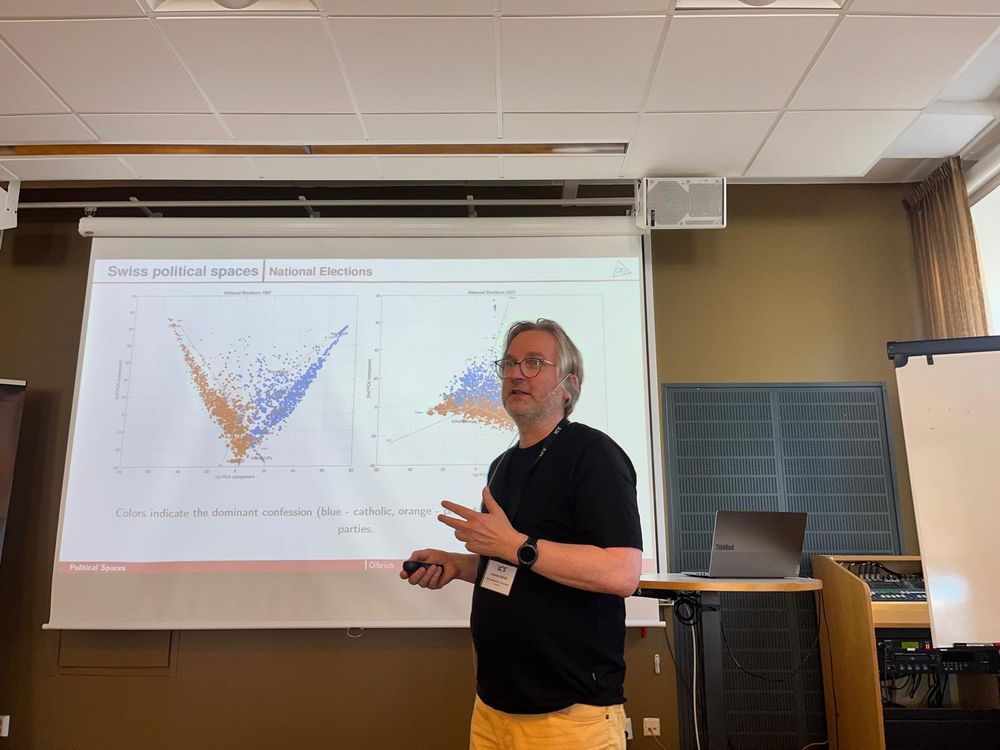
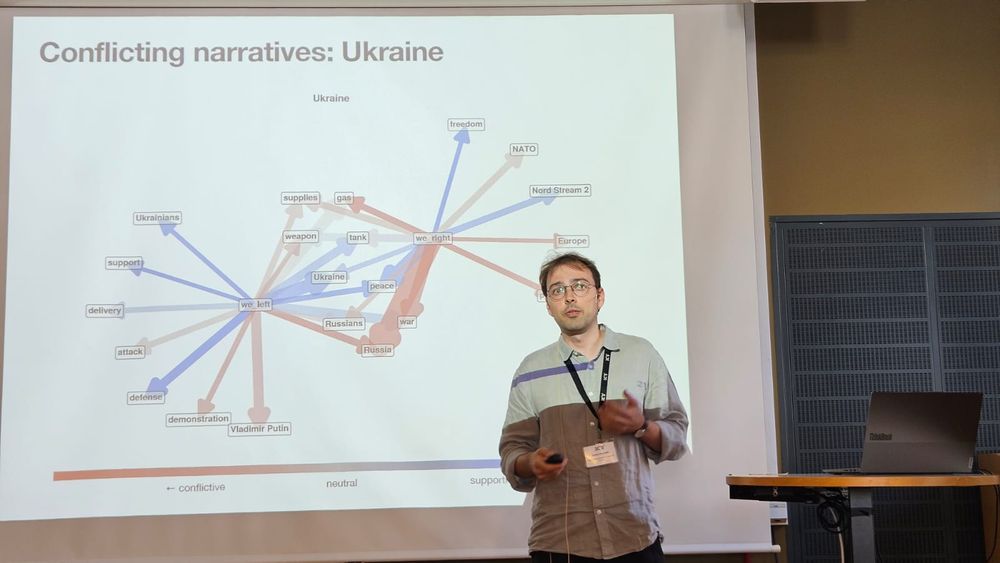
Looking forward to #ic2s2 where I'll present some of our latest work from the @some4dem.bsky.social project:
- Conflicting narratives and polarization (Tue in Pol.Narratives II 2:30pm)
- A political cartography of news sharing (Tue, poster)
- Issue alignment and polarization on Twitter (Thu, poster)
21.07.2025 13:33
👍 17
🔁 2
💬 0
📌 0
Thanks for sharing!
14.05.2025 09:39
👍 1
🔁 0
💬 0
📌 0