
Can self-supervised models 🤖 understand allophony 🗣? Excited to share my new #NAACL2025 paper: Leveraging Allophony in Self-Supervised Speech Models for Atypical Pronunciation Assessment arxiv.org/abs/2502.07029 (1/n)
29.04.2025 17:00
👍 15
🔁 10
💬 2
📌 0
📢 Introducing VERSA: our new open-source toolkit for speech & audio evaluation!
- 80+ metrics in one unified interface
- Flexible input support
- Distributed evaluation with Slurm
- ESPnet compatible
Check out the details
wavlab.org/activities/2...
github.com/wavlab-speec...
28.04.2025 19:50
👍 4
🔁 0
💬 0
📌 0
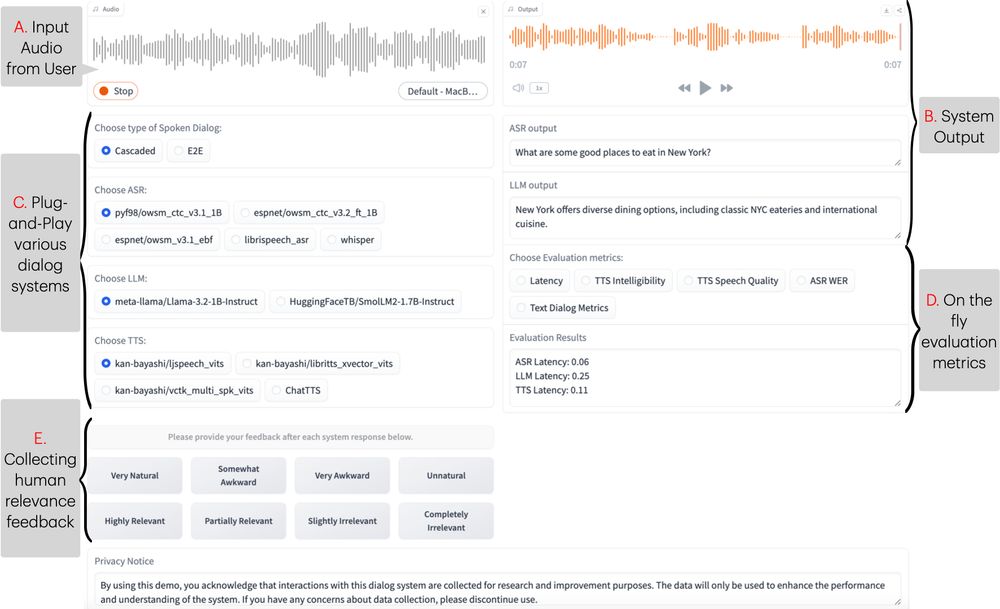
New #NAACL2025 demo, Excited to introduce ESPnet-SDS, a new open-source toolkit for building unified web interfaces for both cascaded & end-to-end spoken dialogue system, providing real-time evaluation, and more!
📜: arxiv.org/abs/2503.08533
Live Demo: huggingface.co/spaces/Siddh...
17.03.2025 14:29
👍 7
🔁 5
💬 1
📌 0
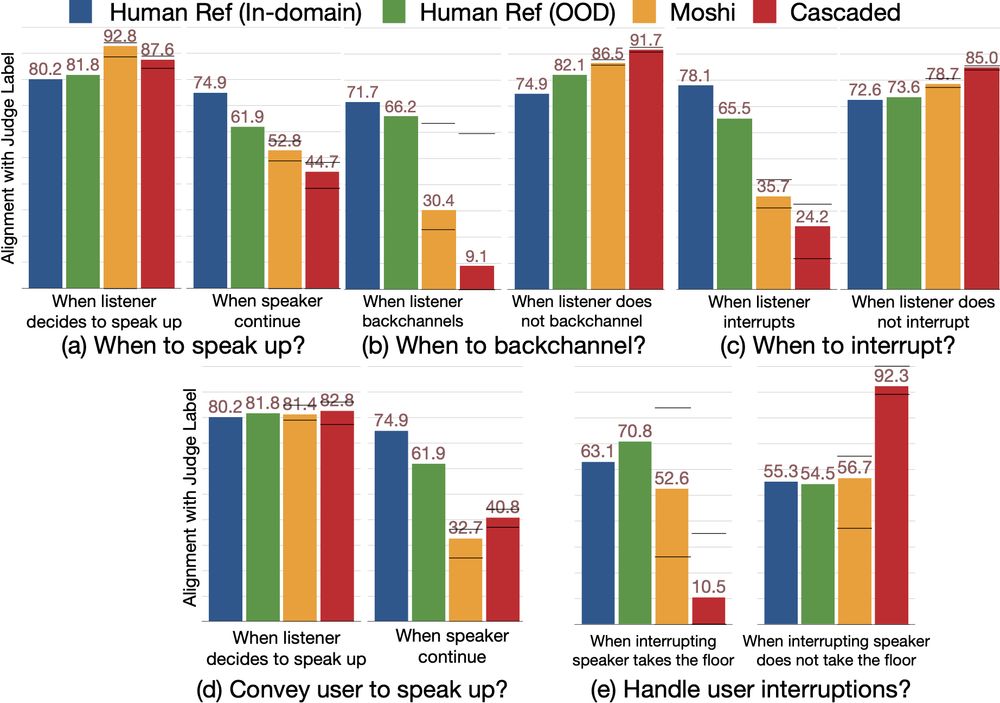
🚀 New #ICLR2025 Paper Alert! 🚀
Can Audio Foundation Models like Moshi and GPT-4o truly engage in natural conversations? 🗣️🔊
We benchmark their turn-taking abilities and uncover major gaps in conversational AI. 🧵👇
📜: arxiv.org/abs/2503.01174
05.03.2025 16:03
👍 9
🔁 6
💬 1
📌 0

📣 #SpeechTech & #SpeechScience people
We are organizing a special session at #Interspeech2025 on: Interpretability in Audio & Speech Technology
Check out the special session website: sites.google.com/view/intersp...
Paper submission deadline 📆 12 February 2025
06.12.2024 21:29
👍 16
🔁 9
💬 1
📌 1
Excited to announce the launch of our ML-SUPERB 2.0 challenge @interspeech.bsky.social 2025! Join us in pushing the boundaries of multilingual ASR and LID! 🚀
💻 multilingual.superbbenchmark.org
04.12.2024 18:09
👍 8
🔁 3
💬 0
📌 0


This is my first official post at Bluesky with great news :)
We got the best paper award at IEEE SLT'24! This work elegantly and straightforwardly solves contextual biasing issues with dynamic vocabulary arxiv.org/abs/2405.13344. Congrats, Yui, Yosuke, Shakeel, and Yifan!
! I'm super happy!
04.12.2024 14:15
👍 40
🔁 7
💬 2
📌 1
Part II
@pzelasko.bsky.social
@smfsamir.bsky.social
@juice500ml.bsky.social
@popcornell.bsky.social
@wanchichen.bsky.social
@holgerbovbjerg.bsky.social
@cromz22.bsky.social
@siddhant-arora.bsky.social
@mmiagshatoy.bsky.social
26.11.2024 20:54
👍 5
🔁 0
💬 0
📌 0
I just collected them (maybe some of them are already there)
Part I
@pengyf.bsky.social
@brianyan918.bsky.social
@albertzeyer.bsky.social
@oplatek.bsky.social
@shikharb.bsky.social
@zaidsheikh.bsky.social
@kalvinchang.bsky.social
26.11.2024 20:54
👍 7
🔁 0
💬 1
📌 0
Multimodal Information Based Speech Processing (MISP) 2025 Challenge
Hi speech people, super exciting news here!
We are running another "Multimodal information based speech (MISP)" Challenge at @interspeech.bsky.social
Participate!
Spread the word!
More info 👇
mispchallenge.github.io/mispchalleng...
25.11.2024 11:25
👍 15
🔁 7
💬 0
📌 0





