
Hello world
26.02.2025 21:08
👍 1
🔁 0
💬 0
📌 0
Hello world

Newton-Schulz isn't the answer even for instantaneous whitening.
PSGD: MSE( Q.T Q H , I ) = 5.2e-3
Zero-Power NS 100 iterations: MSE( NS(G) , I ) = 8.2e-1
True Inverse: MSE( H^(-1/2) H H^(-1/2), I ) = 6.1e-3
PSGD whitens information significantly better than the Newton-Schulz iters found in Muon

Xilin is back at it again. Results are clear: damping hurts precision, but lower precision needs it if the underlying Hessian is extremely poorly conditioned.

PSGD tracking Muon on modded nanoGPT
Be in touch!
Who is going to NeurIPS?
Cheers !
Maybe just a skill issue but I couldn't get the darn thing to run. I wanted to whiten the gradients before giving them to velo to see how effective performance. Would you be interested in helping me with a few experiments?

I was just looking and seems there is also this..
I wish there was code for velo and this that actually worked
arxiv.org/abs/2209.11208
Totally agree!
The rejects were horribly misinformed self contradictory but extremely confident. PSGD, SOAP and friends are taking over regardless of academia.
Lol AI stats reviews consisted of one 5 rating: Top 10% of accepted papers with a confidence or 5 - absolutely certain. The reviewer raved and ranted about how good PSGD.
And two confident 4 rejects with a score of 1. And one borderline reject with a confidence of 4.
Here was a post I made showing MARS actually helping initial convergence of PSGD. I believe this is happening because MARS is reducing the variance of the gradients which here resulted in a bit faster convergence. But it is unclear how this effects PSGD later in training!
bsky.app/profile/hess...
Hi @clementpoiret.bsky.social I am one of the co-authors of PSGD from 2022, and actively working on PSGD Kron with Xilin and @evanatyourservice.bsky.social glad you are excited about PSGD Kron!

PSGD is a bit orthogonal to MARS and such MARS can be easily adopted. Here is a branch that has them combined.
github.com/evanatyourse...
SmolVLM was just released 🚀
It's a great, small, and fully open VLM that I'm really excited about for fine-tuning and on-device use cases 💻
It also comes with 0-day MLX support via mlx-vlm, here's it running at > 80 tok/s on my M1 Max 🤯
Just put together a starter pack for Deep Learning Theory. Let me know if you'd like to be included or suggest someone to add to the list!
go.bsky.app/2qnppia

PSGD ❤️ MARS
MARS is a new exciting variance reduction technique from @quanquangu.bsky.social 's group which can help stabilize and accelerate your deep learning pipeline. All that is needed is a gradient buffer. Here MARS speeds up the convergence of PSGD ultimately leading to a better solution.
Evan is @evanatyourservice.bsky.social
Bro pfp change messes w me so much.

Oftentimes PSGD will be slow to close plasticity resulting in slightly slower convergence but ultimately a better solution.
We are learning the curvature. It can take some time. You can get it to converge faster if you increase the LR of the curvature fitting.
Okayyy I should actually start posting about PSGD here
Hello World!
Hey hey hey the Hessian code is sitting there. I just have to port it to the standard torch.optim style. Right now it uses closure. We can use hvps but we can also use finite differences.
This is only kron whitening btw. We should port the Hessian version too.
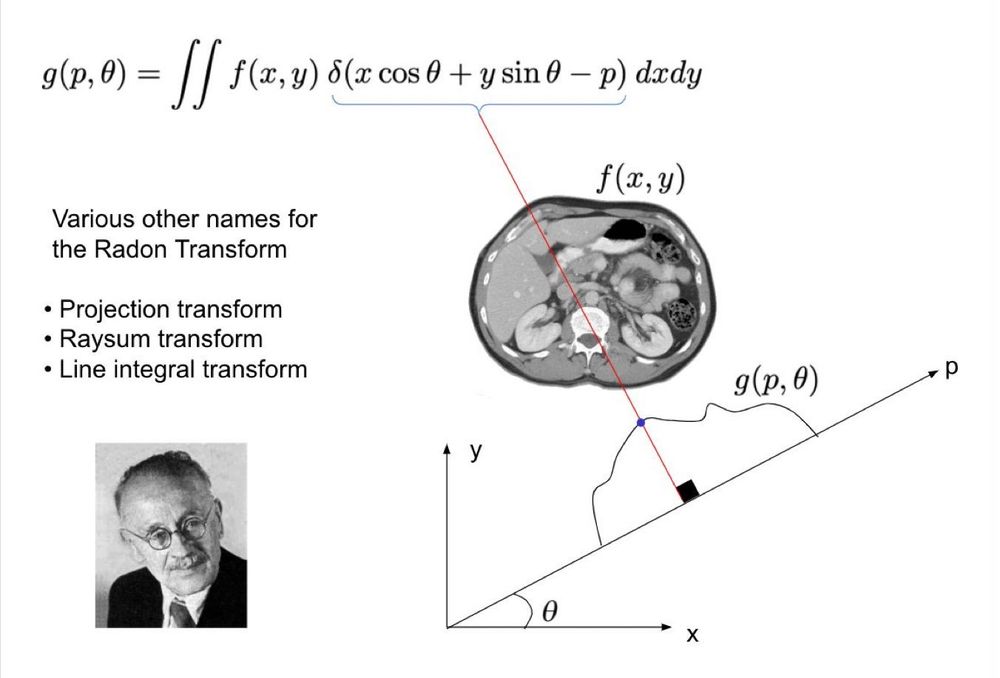
Radon Transform (RT) was formulated in 1917 but remained useless in practice until CT scanners were invented in the 60s
But RT isn't just for CTs. It's a sort of generalization of marginals in probability
RT g(p,θ): Shoot rays at θ+90 & offset p, measure line integrals of f(x,y) along the ray
1/n

Starter packs are helpful as well as the twitter import tool chromewebstore.google.com/detail/sky-f...

Just some light reading
