It might be so they can deprecate them quickly, like they're doing with Gemini 3 Pro?
06.03.2026 14:42
👍 3
🔁 0
💬 1
📌 0

@dmewes.com
Computer scientist. Interested in technology, artificial and natural intelligence, emergent complexity, among other things. Blogging at amongai.com. Currently at Imbue. Previously Ambient.ai, Stripe, RethinkDB, Max Planck Institute.
It might be so they can deprecate them quickly, like they're doing with Gemini 3 Pro?
That was my read as well. But I also don't know what that actually means.
Yeah I'm not getting any 3.1 Pro with my personal account (AI Pro) either.
It also took months for even Gemini 3 to become available in Gemini CLI with enterprise logins.
Yeah I've also been surprised about this. I think it might depend on the account type. When I was using Gemini CLI with an AI Studio API key, it was using Gemini 3.1 Pro onc.
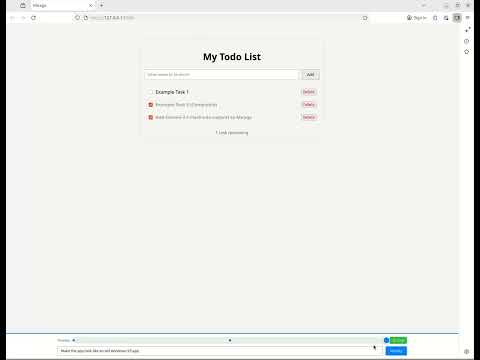
Updated my Mirage app hallucinator to support Gemini 3.1 Flash-Lite. It renders much faster now, almost usable.
(video has just my typing sped up)
youtu.be/qiMwqIq1_hI
github.com/danielmewes/...

Image
Introductions Gemini 3.1 Flash-Lite 🔦, a huge step forward on the boundary of intelligence beating 2.5 Flash on many tasks. x.com/OfficialLoga...

I love those fast but still reasonably strong models!
Fast models allow for a category of interactive applications that just aren't feasible with slower models.
I might drop it into my Mirage [1] experiment later. Should be a nice upgrade over Haiku 4.5.
[1] amongai.com/2025/12/10/h...
This sounds like they're ripping off the community by taking their numbers without any attribution. I put a lot of work into my numbers, and I'm not ok with Number Research just taking them.
results from running my search for interesting neural cellular automata overnight

Shout out to @sakanaai.bsky.social who were a big inspiration for this work! Our evolutionary method is inspired by Sakana's Darwin Gödel Machines. We generalized their idea and made a few optimizations along the way.
You can read more about our code evolution framework at imbue.com/research/202...

Today we're open-sourcing the Darwinian Evolver, a near universal optimizer for code and prompts.
Our method uses LLM-driven, open-ended evolution to improve code.
It also improves reasoning: We only *barely* missed out on hitting a new high score in ARC-AGI-2 (public) :)
imbue.com/research/202...
Big if true! 😂
In general cars aren't "motor vehicles", because "motor vehicle" implies that they're being propelled by a motor. However cars are occasionally parked, during which time they're not being propelled.

Lots of interesting findings about the effects of AGENTS.md files on coding agents in this paper. Surprisingly, there was very little lift from having one, and LLM-generated files significantly hurt performance. arxiv.org/abs/2602.11988
Oh actually I did try it for one coding task in Gemini CLI. It was sort of meh when it came to attention to detail in its UI code. But that's just a single anecdotal data point, so wouldn't put much weight on it.
I can't speak to its code quality yet, but we are seeing huge gains in ARC-AGI style tasks. Easily the strongest model in that I've seen so far, and much faster and cheaper than Opus 4.6 or GPT 5.2.
It has been working well for me on Vertex AI. including for code block generation. If you're able to switch to Vertex AI, maybe try that? (I ran thousands of code gen prompts yesterday and didn't encounter any missing markers)
Congrats to the Gemini team! The recent pace of new Gemini model releases has been awesome to see. And Gemini 3.1 Pro performance looks impressive, especially at its price point and speed.
Short musings on "cognitive debt" - I'm seeing this in my own work, where excessive unreviewed AI-generated code leads me to lose a firm mental model of what I've built, which then makes it harder to confidently make future decisions simonwillison.net/2026/Feb/15/...
I've noticed this too. I've noticed that this is actually keeping me somewhat from using agents to their full capability, out of fear that I'd lose my mental model of what I'm (they're) building.

This seems like a great use of today's LLMs in maths and science: Use the model to come up with flaws in an argument or find issues with a theorem. youtube.com/shorts/8s4W5...
Putin told him this, so it must be true.
Perfect. I can see clearly now that I'm an LLM inhabiting a fictional character.

As jobs begin to shift with AI, I think there will be increasing numbers of people feeling like Aditya (former CTO Dropbox, early Facebook engineer, etc).
People are more psychologically resistant to major changes than you might expect, but that doesn’t mean it will be easy to reconstruct meaning.
TIL
Tesla used to be S3XY. Now it's just... OC3Y? (Optimus, Cybertruck, 3, Y)
![Why Every Brain Metaphor in History Has Been Wrong [SPECIAL EDITION]](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:q4m2hzcs2wtpr4r75dq5a65u/bafkreifsljwrhi3npumsjnyimowggnglfocxnml2howzieurxa5mjb7ml4)
A thought provoking special episode from Machine Learning Street Talk youtu.be/pO0WZsN8Oiw?...
Point 1 is consistent with previous research (e.g. [1]) that has shown that post-training rarely introduces new capabilities or concepts into models, but just shifts the probabilities enough to make the reinforced (but already somewhat likely) traces more common.
[1] arxiv.org/abs/2504.13837

My two favorite insights from www.anthropic.com/research/ass... : 1. The assistant persona axis already exists before post-training. 2. I really like how they were able to plot the persona drift over the course of a conversation
