
Looking for a small or medium sized VLM? PaliGemma 2 spans more than 150x of compute!
Not sure yet if you want to invest the time 🪄finetuning🪄 on your data? Give it a try with our ready-to-use "mix" checkpoints:
🤗 huggingface.co/blog/paligem...
🎤 developers.googleblog.com/en/introduci...
19.02.2025 17:47
👍 19
🔁 7
💬 0
📌 0
Thank you!
21.12.2024 08:21
👍 5
🔁 0
💬 0
📌 0
x.com
Also check out this concurrent work that is very similar in spirit to Jet and JetFormer, which proposes autoregressive ViT-powered normalizing flows (NFs): x.com/zhaisf/statu...
20.12.2024 14:39
👍 6
🔁 0
💬 0
📌 0
Joint work with @asusanopinto.bsky.social
and @mtschannen.bsky.social performed at Google Deepmind.
20.12.2024 14:39
👍 2
🔁 0
💬 1
📌 0
Final note: we see the Jet model as a powerful tool and a building block for advanced generative models, like JetFormer bsky.app/profile/mtsc..., and not as a standalone competitive generative model.
20.12.2024 14:39
👍 1
🔁 0
💬 1
📌 0


When trained on 'small' data, such as ImageNet-1k, overfitting occurs.
Another contribution is a demonstration that transfer learning is effective in mitigating overfitting. The recipe is: pretrain on a large image database and then fine-tune to a small dataset, e.g., CIFAR-10.
20.12.2024 14:39
👍 2
🔁 1
💬 1
📌 0
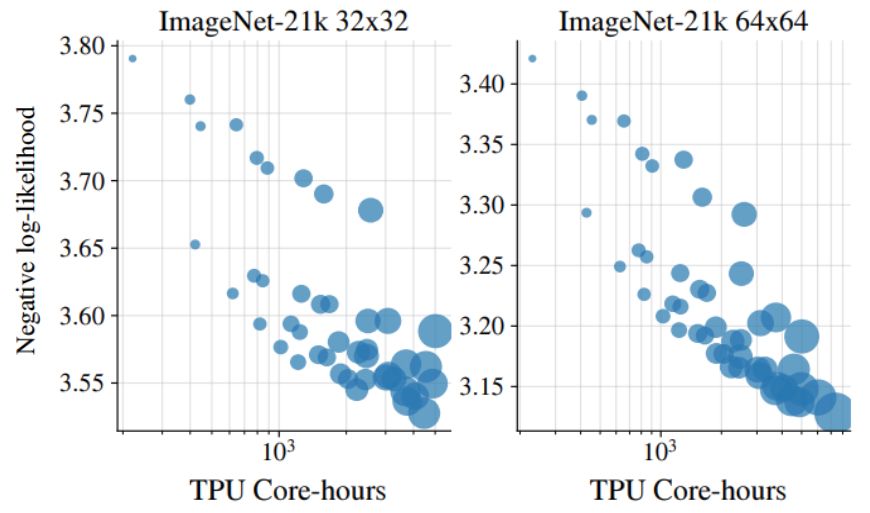
We observe robust performance improvements with compute scaling, showing behavior similar to classical scaling laws.
These are the results of varying the Jet model size when training on ImageNet-21k images:
20.12.2024 14:39
👍 2
🔁 0
💬 1
📌 0

Our main contribution is a very straightforward design: Jet is just repeated affine coupling layers with ViT inside. We show that many standard components are not needed with our simple design:
❌ invertible dense layer
❌ ActNorm layer
❌ multiscale latents
❌ dequant. noise
20.12.2024 14:39
👍 3
🔁 1
💬 1
📌 0

With some delay, JetFormer's *prequel* paper is finally out on arXiv: a radically simple ViT-based normalizing flow (NF) model that achieves SOTA results in its class.
Jet is one of the key components of JetFormer, deserving a standalone report. Let's unpack: 🧵⬇️
20.12.2024 14:39
👍 42
🔁 7
💬 2
📌 1
Paligemma2 is out! Bigger models, better results. For the best experience, do not forget to finetune.
Congrats Paligemma2 team!
05.12.2024 18:28
👍 13
🔁 1
💬 0
📌 0
Ok, it is yesterdays news already, but good night sleep is important.
After 7 amazing years at Google Brain/DM, I am joining OpenAI. Together with @xzhai.bsky.social and @giffmana.ai, we will establish OpenAI Zurich office. Proud of our past work and looking forward to the future.
04.12.2024 09:14
👍 116
🔁 11
💬 8
📌 5
In arxiv.org/abs/2303.00848, @dpkingma.bsky.social and @ruiqigao.bsky.social had suggested that noise augmentation could be used to make other likelihood-based models optimise perceptually weighted losses, like diffusion models do. So cool to see this working well in practice!
02.12.2024 18:36
👍 53
🔁 11
💬 0
📌 0
The answer has just dropped: bsky.app/profile/kole...
02.12.2024 19:00
👍 15
🔁 2
💬 2
📌 0
JetFormer product of endless and heated (but friendly) arguing and discussions with @mtschannen.bsky.social
and @asusanopinto.bsky.social.
Very excited about this model due to its potential to unify multimodal learning with a simple and universal end-to-end approach.
02.12.2024 17:19
👍 1
🔁 0
💬 0
📌 0
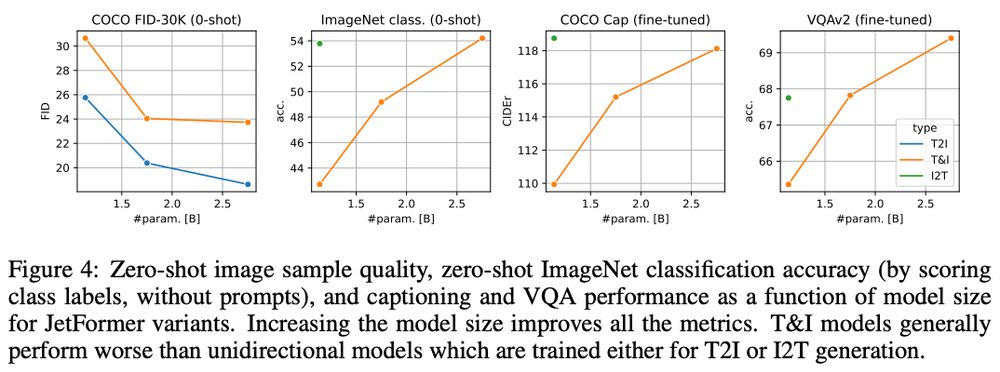
We evaluate JetFormer potential to model large-scale multimodal image+text data and do image-to-text, text-to-image and VQA tasks, and get rather encouraging results.
02.12.2024 17:19
👍 1
🔁 0
💬 1
📌 0
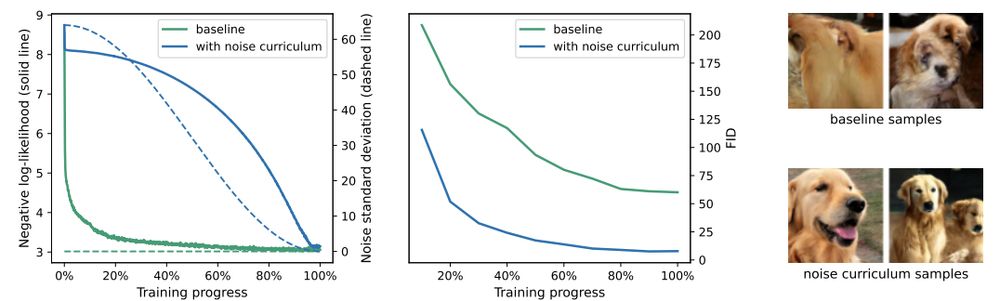
We also present novel data augmentation: "noise curriculum". It helps a pure NLL model to focus on high-level image details.
Even though it is inspired by diffusion, it is very different: it only affects training and does not require iterative denoising during inference.
02.12.2024 17:19
👍 2
🔁 0
💬 1
📌 0
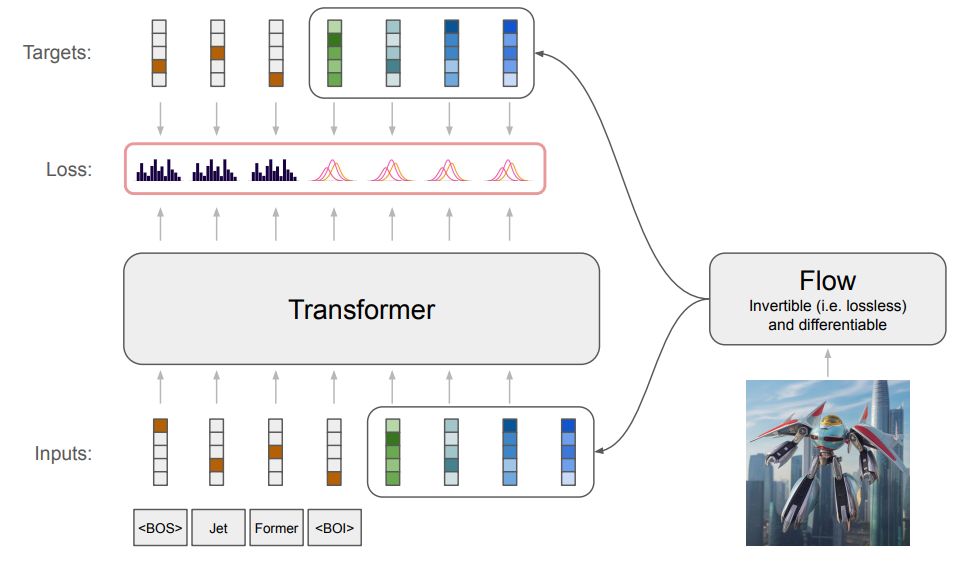
JetFormer is just an autoregressive transformer, trained end-to-end in one go, with no pretrained image encoders/quantizers.
There is a small twist though. An image input is re-encoded with a normalizing flow model, which is trained jointly with the main transformer model.
02.12.2024 17:19
👍 2
🔁 0
💬 1
📌 0
I always dreamed of a model that simultaneously
1. optimizes NLL of raw pixel data,
2. generates competitive high-res. natural images,
3. is practical.
But it seemed too good to be true. Until today!
Our new JetFormer model (arxiv.org/abs/2411.19722) ticks on all of these.
🧵
02.12.2024 17:19
👍 37
🔁 5
💬 2
📌 0



