Distributed Inference Meetup NYC · Luma
llm-d Distributed Inference Meetup NYC Hosted by Red Hat AI, IBM Research, and AMD, this event takes place on March 11, 2026 in New York City. What to…
Planning to join us in NYC next week? 🏙️
Registration for the llm-d Distributed Inference Meetup closes this Tuesday, March 10th.
Don't miss out on a night of technical talks and networking with the community at the IBM 1 Madison office. Grab your spot now!
🎟️ luma.com/0crwqwg4
#llmd #NYCMeetup
06.03.2026 14:15
👍 0
🔁 0
💬 0
📌 0
Distributed Inference Meetup NYC · Luma
llm-d Distributed Inference Meetup NYC Hosted by Red Hat AI, IBM Research, and AMD, this event takes place on March 11, 2026 in New York City. What to…
What’s on the agenda for next Wednesday's NYC meetup?
🛠️ Intro to llm-d 0.5
⚡️ Distributed LLM serving on AMD
🧠 Lessons scaling Wide-EP and MoE
💾 KV-cache offloading & prefix scheduling
Join the engineers building the future of open-source inference.
Details: luma.com/0crwqwg4
04.03.2026 14:17
👍 1
🔁 0
💬 0
📌 0

Distributed Inference Meetup NYC · Luma
llm-d Distributed Inference Meetup NYC
Hosted by Red Hat AI, IBM Research, and AMD, this event takes place on March 11, 2026 in New York City.
What to…
Join us next week in NYC with the llm-d community for a deep dive into distributed inference.
We’re talking llm-d 0.5, scaling MoE models, and KV-cache offloading.
If you're building LLM infra, don't miss this.
📅 March 11th
📍1 Madison Ave
Register: luma.com/0crwqwg4
02.03.2026 15:57
👍 1
🔁 0
💬 0
📌 1
Optimizing LLM Workloads: A Deep Dive into the GPU Recommendation Tool & Configuration Explorer
YouTube video by llm-d Project
In the latest llm-d release, we’re tackling high hardware costs with the new GPU Recommendation Tool! 📈
Evaluate throughput, latency, and cost-effectiveness before requesting expensive cluster resources.
Check out the full demo: www.youtube.com/watch?v=Y26i...
24.02.2026 19:17
👍 2
🔁 1
💬 0
📌 0

Upcoming llm-d Events | llm-d
Meet the llm-d community at upcoming talks, meetups, and conferences
There are many more sessions and community meetups happening throughout the year.
Check the full calendar for session details, room numbers, and the complete list of talks from the llm-d community:
🔗 llm-d.ai/docs/communi...
19.02.2026 20:14
👍 1
🔁 0
💬 0
📌 0

PyTorch Conference Europe | LF Events
Join top-tier researchers, developers, and academics for a deep dive into PyTorch, the cutting-edge open-source machine learning framework.
📍 Stop 3: PyTorch Conference Europe
📅 April 7–8 | Paris
Deep technical tracks on chunked decoding, preemptive scheduling, and disaggregated tokenization. We'll be sharing the latest on state-aware serving with vLLM + llm-d.
Full Schedule: events.linuxfoundation.org/pytorch-conf...
19.02.2026 20:14
👍 1
🔁 0
💬 1
📌 0

KubeCon + CloudNativeCon Europe | LF Events
The Cloud Native Computing Foundation’s flagship conference gathers adopters and technologists from leading open source and cloud native communities.
📍 Stop 2: KubeCon Europe
📅 March 23–26 | Amsterdam
From Istio Day to the main stage, we’re talking AI-aware routing and KV-cache scheduling. Don't miss our tutorial on building resilient LLM gateways with Kubernetes.
Details: events.linuxfoundation.org/kubecon-clou...
19.02.2026 20:14
👍 0
🔁 0
💬 1
📌 0

Distributed Inference Meetup NYC · Luma
llm-d Distributed Inference Meetup NYC
Hosted by Red Hat AI, IBM Research, and AMD, this event takes place on March 11, 2026 in New York City.
What to…
📍 Stop 1: NYC Distributed Inference Meetup
📅 March 11 | IBM Innovation Studio
We’re diving into the weeds of llm-d 0.5, Wide-EP, and MoE model scaling. Perfect for anyone in the city looking to optimize LLM serving on AMD and beyond.
Register: luma.com/0crwqwg4
19.02.2026 20:14
👍 0
🔁 0
💬 1
📌 0
Where to find the llm-d community over the next 2 months 🧵
We have a busy Spring ahead with sessions in NYC, Amsterdam, and Paris. If you're building open-source infrastructure for distributed inference, come join the conversation. ⬇️
19.02.2026 20:14
👍 0
🔁 0
💬 1
📌 0
Distributed Inference Meetup NYC · Luma
llm-d Distributed Inference Meetup NYC
Hosted by Red Hat AI, IBM Research, and AMD, this event takes place on March 11, 2026 in New York City.
What to…
The agenda is still evolving, and we’ve got even more awesomeness in the works! 📈
Whether you're running GenAI in production or building the platforms to support it, this is the room to be in.
📅 March 11 | 4:30 PM
📍 1 Madison Ave, NYC
🎟️ RSVP: luma.com/0crwqwg4
16.02.2026 17:13
👍 0
🔁 1
💬 0
📌 1
Hosted by Red Hat AI, IBM Research, and AMD. 🤝
If you're building or scaling models, this event is for you.
We’re bringing together maintainers and engineers working on:
🔹 llm-d project roadmap
🔹 Optimizing for AMD hardware
🔹 Scaling MoE (Mixture-of-Experts)
🔹 KV-Cache & Prefix-caching performance
16.02.2026 17:13
👍 0
🔁 0
💬 1
📌 0
NYC: Ready to go deep on Distributed Inference? 🗽
The llm-d community is hitting Manhattan on March 11th!
Join us at the IBM Innovation Studio for a technical deep dive into the infra powering the next generation of LLM serving. 🧵
16.02.2026 17:13
👍 1
🔁 1
💬 1
📌 0
[Announcement] WG Serving Has Succeeded and Will Be Disbanded
We'd like to announce that @kubernetes.io WG Serving has succeeded and will be disbanded! Thank you everyone who have participated and contributed to the discussions and initiatives!
More details: groups.google.com/a/kubernetes...
13.02.2026 15:28
👍 4
🔁 2
💬 1
📌 1
In case you missed it, last week the llm-d community shipped the v0.5 release.
Check out the post from the llm-d project owners to learn more about all the features we've included in this release.
llm-d.ai/blog/llm-d-v...
09.02.2026 17:52
👍 1
🔁 1
💬 0
📌 0
👉 Check out the February newsletter here: https://inferenceops.substack.com/p/state-of-the-model-serving-communities-f81
👉 Subscribe to get future issues in your inbox: https://inferenceops.substack.com/
🚀 Thanks to everyone who subscribed so far!
Kudos to all contributors to this edition!
09.02.2026 14:47
👍 0
🔁 1
💬 1
📌 0
Our goal with this newsletter is to give a clear, community-driven view of what’s happening across the model serving ecosystem, including updates from vLLM, KServe, @llm-d.ai, @kubernetes.io, and Llama Stack.
09.02.2026 14:46
👍 0
🔁 1
💬 1
📌 0

GitHub - llm-d/llm-d: Achieve state of the art inference performance with modern accelerators on Kubernetes
Achieve state of the art inference performance with modern accelerators on Kubernetes - llm-d/llm-d
This release is built on collaboration—from NIXL 0.9 merges to vLLM integrations.
We are building an open, hardware-agnostic inference control plane.
Ready to build? 🧱
GitHub: github.com/llm-d/llm-d
Website: llm-d.ai
Community Calls: Wed 12:30pm ET
05.02.2026 15:32
👍 0
🔁 0
💬 0
📌 0

🌐 In disaggregated serving, network congestion kills tail latency.
We’ve integrated the UCCL backend into NIXL, demonstrating 2.4x greater resilience to network contention than standard transports.
05.02.2026 15:32
👍 0
🔁 0
💬 1
📌 0

🎯 Multi-tenant workloads often suffer from the "thundering herd" problem.
v0.5 introduces LoRA-precise prefix caching, routing requests based on specific cache locality to maximize efficiency.
05.02.2026 15:32
👍 0
🔁 0
💬 1
📌 0

⚖️ Standard deployments collapse when memory is saturated. Our new Hierarchical KV Offloading creates a "performance floor" using a three-tier hierarchy (GPU, CPU, Disk).
We sustained ~185k tok/s during high concurrency—a 13.9x improvement.
05.02.2026 15:32
👍 0
🔁 0
💬 1
📌 0

Realized production performance shouldn't be a mystery.
We've adopted the "Research Paper Principle": every claim in v0.5 is backed by a reproducible, version-controlled configuration you can validate with one command. ⚙️
05.02.2026 15:32
👍 0
🔁 0
💬 1
📌 0
llm-d 0.5: Sustaining Performance at Scale | llm-d
Announcing the llm-d 0.5 release
🏗️ llm-d v0.5: Sustaining Performance at Scale In our last release, we focused on breaking latency records.
With v0.5, we’re shifting from peak performance to the operational rigor required to sustain those gains in production.
🧵👇
llm-d.ai/blog/llm-d-v...
05.02.2026 15:32
👍 1
🔁 1
💬 1
📌 1

Inference OSS Ecosystem featuring llm-d | Other 2026 | NVIDIA On-Demand
This session introduces llm-d, a distributed open-source framework for LLM inference
Check out this recent talk from IBM Distinguished Engineer and llm-d project lead Carlos Costa at NVIDIA Dynamo Day. Breaking down our approach to open-source inference, moving beyond theory to provide verified blueprints for scaling LLMs in production.
red.ht/4kjqGty
02.02.2026 17:11
👍 0
🔁 0
💬 0
📌 0
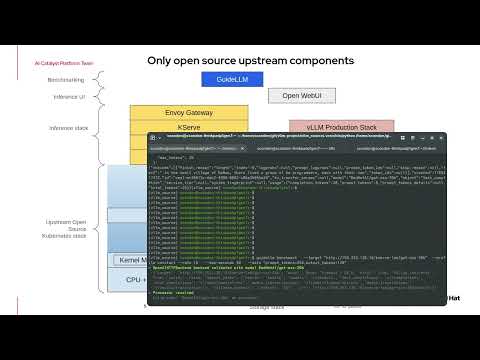
We put the stack to the test on NVIDIA A100s:
🔹 KServe + llm-d: Optimizing distribution across replicas.
🔹 vLLM Production Stack: Testing cache-aware routing and MIG partitions for mixed workloads.
Open source for the most demanding AI use cases
youtu.be/OinY1Oooke0
26.01.2026 22:28
👍 0
🔁 0
💬 0
📌 0
The demo shows how llm-d serves as the core layer in a modular architecture, integrating with key upstream projects:
🚀 vLLM: High-perf engine
⚖️ llm-d: Multi-replica load balancing
📦 KServe: Orchestration
🌐 Envoy Gateway: Intelligent request routing
📊 Grafana: Deep o11y
26.01.2026 22:28
👍 0
🔁 0
💬 1
📌 0
Scaling prod LLM inference shouldn't require a proprietary ecosystem.
We’re demonstrating how a fully open-source stack handles high-performance, distributed workloads on Kubernetes.
Huge shout-out to Sean Condon from @RedHat for this deep dive! 📺 youtu.be/OinY1Oooke0
26.01.2026 22:28
👍 0
🔁 0
💬 1
📌 0
Community Demo: Verified & Reproducible LLM Benchmarks | llm-d Project
In the llm-d open-source project, we believe a supported guide is only as good as the data backing it. In this community demo, the SIG-benchmarking team showcases the benchmarking suite that brings…
A huge shoutout to the contributors in SIG-benchmarking for making performance transparency a core pillar of the llm-d project!
🚀 Check out the full demo here: youtu.be/TNYXjZpLCN4
#AI #Kubernetes #Benchmarking
19.01.2026 20:13
👍 0
🔁 0
💬 0
📌 0
⚫ 100% Reproducibility: We aim for a world where if you see a benchmark in an llm-d blog post, you can run the exact same template on your cluster and see the same results. Transparency is key to scaling AI.
19.01.2026 20:13
👍 0
🔁 0
💬 1
📌 0

Why does this matter for the community?
⚫ Verified, Not Just Documented: Every community-tested guide is now backed by standardized benchmarking templates.
If the guide says it performs, we provide the tools to prove it.
19.01.2026 20:13
👍 0
🔁 0
💬 1
📌 0

This new contribution allows anyone to benchmark a pre-existing or pre-installed stack. It is specifically designed for stacks deployed via official llm-d guides to ensure your setup matches our verified community baselines.
19.01.2026 20:13
👍 0
🔁 0
💬 1
📌 0