
Happy holidays everyone! What would you want to see more from Hugging Face in 2025?
24.12.2024 12:24
👍 23
🔁 2
💬 8
📌 0
Happy holidays everyone! What would you want to see more from Hugging Face in 2025?

People are flexing their end of year stats, so I made this app to show @hf.co hub stats in a tidy design!
Thanks @jfcalvo.hf.co and @ameeelie.bsky.social for the feature!
This is the power of open research and open-source AI:
huggingface.co/spaces/Huggi...

Just 10 days after o1's public debut, we’re thrilled to unveil the open-source version of the technique behind its success: scaling test-time compute
By giving models more "time to think," Llama 1B outperforms Llama 8B in math—beating a model 8x its size. The full recipe is open-source!
Who’s at #neurips2024 and want to meet HF team members?
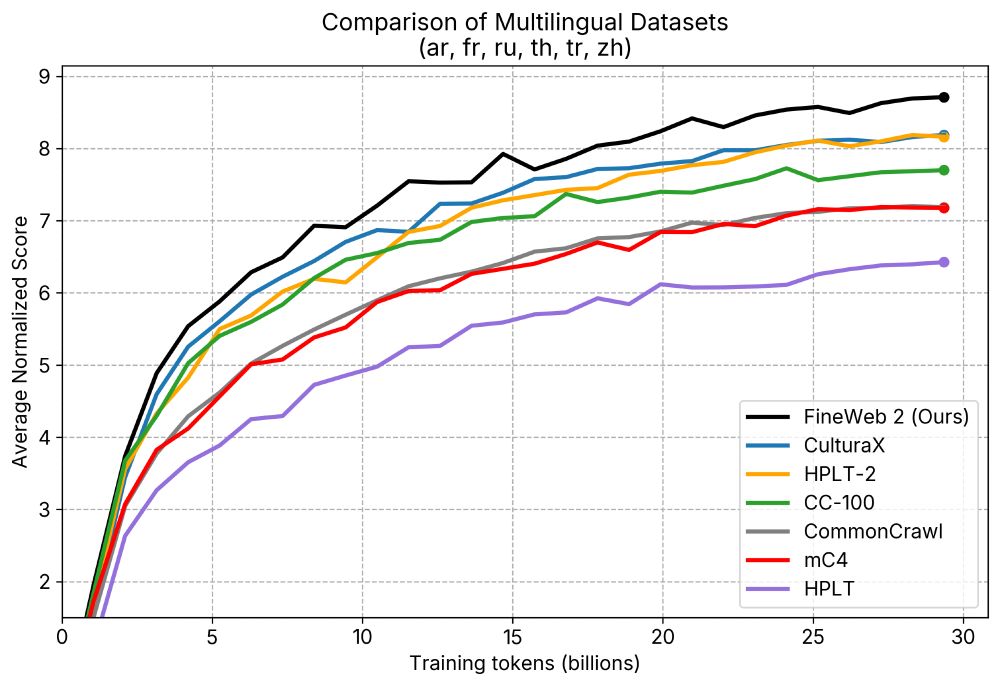
Announcing 🥂 FineWeb2: A sparkling update with 1000s of 🗣️languages.
We applied the same data-driven approach that led to SOTA English performance in🍷 FineWeb to thousands of languages.
🥂 FineWeb2 has 8TB of compressed text data and outperforms other datasets.
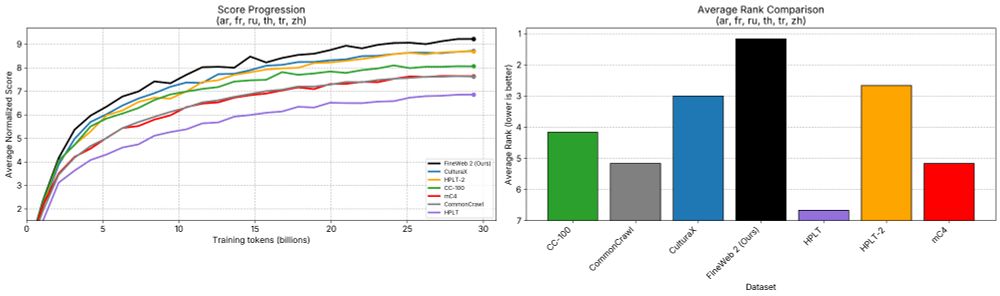
The FineWeb team is happy to finally release "FineWeb2" 🥂🥳
FineWeb 2 extends the data driven approach to pre-training dataset design that was introduced in FineWeb 1 to now covers 1893 languages/scripts
Details: huggingface.co/datasets/Hug...
A detailed open-science tech report is coming soon

world map with points of interest
The folks at Foursquare released a @hf.co dataset of 104.5 million places of interest and here's all of them plotted using datashader


I weirdly love this! #5 trending on HF right now

Excited to see more biology open-source models for real positive use-cases of AI!
Chai does structure predictions at AlphaFold3 levels of accuracy and able to handle multi-peptide or peptide-ligand complexes rather than just single chains.
Apache 2.0 on HF huggingface.co/chaidiscover...
Very cool! Will share it in the coming days!

🤖 6 AI Predictions for 2025 by Hugging Face CEO
#HuggingFace
#ClementDelangue
#ArtificialIntelligence
www.cosmico.org/6-ai-predict...
Let's make AI more inclusive.
At @huggingface.bsky.social we'll launch a huge community sprint soon to build high-quality training datasets for many languages.
We're looking for Language Leads to help with outreach.
Find your language and nominate yourself:
forms.gle/iAJVauUQ3FN8...

How my predictions for 2024 turned out:

Six predictions for AI in 2025 (and a review of how my 2024 predictions turned out):
I would put this even more strongly: open source AI is probably our only realistic chance to avoid a terrifying increase in concentration of power. I do not want to live in a world where the people with all the money also have all the intellectual power.
Good list if you want to understand AI! go.bsky.app/Nik64nt

QwQ is #1 trending on @hf.co!
This demo of structured data extraction running on an LLM that executes entirely in the browser (Chrome only for the moment since it uses WebGPU) is amazing
My notes here: simonwillison.net/2024/Nov/29/...
Wasn't going to wade into this but... as long as the internet exists in an open form, scraping will exist, and that's kind of the whole point... APIs exist because interacting with data is valuable and scraping (the old fashioned way) is annoying.

For me, the biggest risk in AI is centralization of power and benefits in the hands of a few. This is why at @hf.co, we've been investing on building online courses for as many people as possible to understand and learn to build AI themselves. You can find some of them here: huggingface.co/learn
The most realistic reason to be pro open source AI is to reduce concentration of power.
I’m thankful for everyone using Bluesky, everyone building on atproto, everyone listening to our message and sharing our dream of a better social media ecosystem that puts people first. We’re going to do this together — thanks for joining us on this journey!
A dataset of 1 million or 2 million Bluesky posts is completely irrelevant to training large language models.
The primary usecase for the datasets that people are losing their shit over isn't ChatGPT, it's social science research and developing systems that improve Bluesky.
Did you know that 99% of email today is spam? Your inbox isn’t 99% spam because AI is used to filter it.
The same 99% will happen here too, but if AI researchers continue to get perma-banned for making available the datasets needed to filter it, it’s going to make this platform unusable.
good to have you here!
I'm really sorry you feel that way! If bluesky had a setting where you could opt-out from your posts being used externally, do you think that would help? It probably wouldn't be respected by all but we would definitely try to enforce this at Hugging Face!

you can report the dataset and our legal and moderation team will take a look: huggingface.co/datasets/inf...
new post: bluesky vs. huggingface for normal people
jessbpeck.com/posts/bluesk...
anytime i spend less than 5 months on a thing you know i have opinions.
anyway, as always, feel free to argue with me/complain at me/ point out errors.
Hi, so I've spent the past almost-decade studying research uses of public social media data, like e.g. ML researchers using content from Twitter, Reddit, and Mastodon.
Anyway, buckle up this is about to be a VERY long thread with lots of thoughts and links to papers. 🧵
